Backpropagation을 직접 구현하는 과정에서 이유 없이 갑자기 발생하는 행렬 전치(Transpose)와 관련된 의문점이 오랜 기간 절 괴롭혔습니다.
Backpropagation을 하기 위해서 Cost Function을 해당 계층의 W(가중치)로 편미분 한 후, 현재 W를 수정하는 수식을 유도하는 과정에서 일부 행렬이 전치행렬로 갑자기 변경됩니다. 문제는 제가 행렬이 전치(Transpose)되는 근거와 기준을 이해할 수가 없다는 것입니다.
딥러닝 책이나 웹 문서를 찾아보면 “편미분 과정에서 적당히 행렬을 맞춰준다.“라는 표현으로 이 부분을 설명합니다. 제가 찾고 싶었던 답은 Backpropagation 미분 과정에서 행렬의 방향성(Transpose 할 것이나 말 것이냐)은 어떻게 결정되는가입니다. 사실 이런 문제는 제가 수포자이기 때문에 발생하는 문제였고, 결론은 정말 간단한 것이었습니다. 이 부분을 기록 차원에서 정리해 보겠습니다.
문제: 행렬의 Transpose 왜 발생?
예제로 사용하기 위한 간단한 네트워크를 다음과 같이 정리하겠습니다.
문제를 단순화하기 위해서 가장 가난한 형태로 네트워크를 이용합니다.
Layer: 2
Input Feature: 2
Network Type: Logistic Regression(Binary Classification, 이진 분류)
Activation Function: sigmoid
cost function: Mean Square Error(MSE)
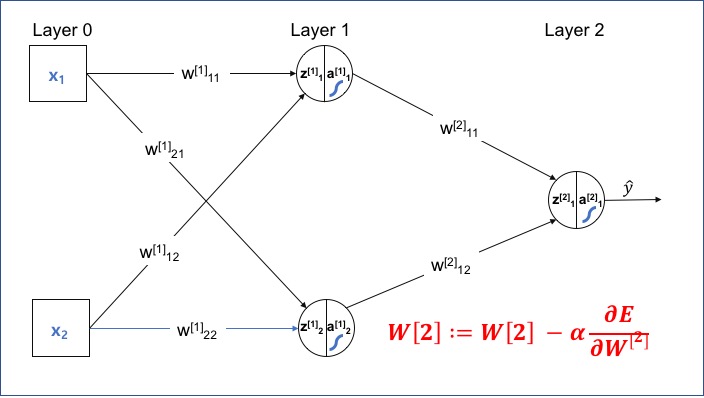
예제로 사용할 신경망은 <그림 1>과 같습니다.
그림 1:
예제 신경망
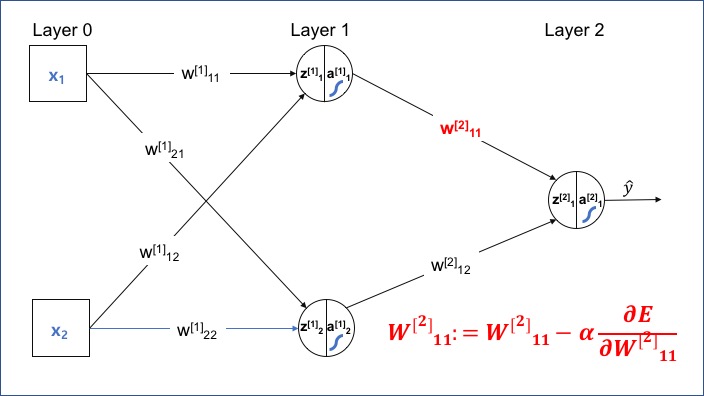
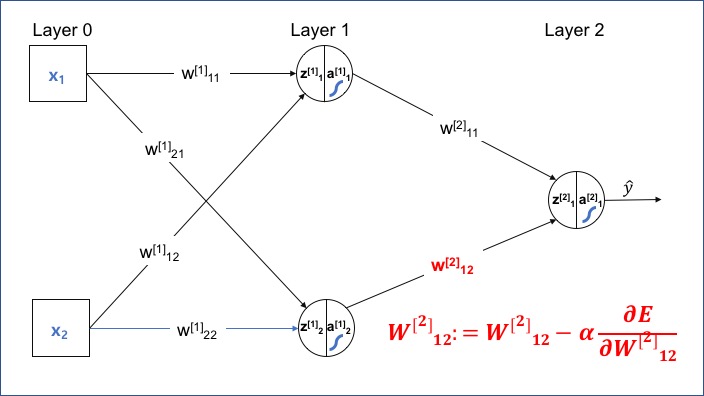
<그림 1> 네트워크에서 두 번째 레이어의 Weight($W^{[2]}$)가 오차에 미치는 영향을 알아보고, Layer 2의 $W^{[2]}$를 업데이트하는 식을 유도해 보겠습니다.
<식 11>는 결과적으로 <식 5>와 동일한 수식임을 알 수 있습니다.
행렬이 포함된 Cost 함수를 W로 미분한 결과와 W의 개별 요소로 Cost 함수를 미분한 후 개별 수식을 행렬로 정리한 결과가 같음을 확인할 수 있습니다.
행렬이 전치되는 이유는 행렬을 미분한 결과가 아니다.
처음에 제가 의문을 가졌던 부분은 Cost를 W로 미분하는 과정에서 행렬이 전치 기준이었습니다. 행렬이 포함된 식을 미분하는 과정에서 특정 행렬이 전치되는 기준과 이유를 명확히 하는 것 있습니다.
결과적으로 행렬을 미분하는 과정에서 행렬이 전치되는 것이 아니라, 각 W의 요소를 미분하고 그 결과 “수식을 선형대수의 행렬로 단순화하는 과정에서 행렬의 Shape이 결정된다“가 결론입니다.
행렬은 여러개의 연산을 한번에 표기하고 처리할 수 있는 수학적 툴입니다. 따라서 각 요소가 수행되는 반복적인 계산을 하나의 표기법으로 처리하고 연산할 수 있는 방식을 제공하는 것이 선형대수의 역할입니다.
처음 제 질문은 결과적으로 잘못된 것이었습니다. 미분 과정에서 행렬이 전치되는 것이 아니라, 각 요소의 연산을 선형대수화하는 과정에서 행렬의 shape이 결정되고 전치되는 것이었습니다.
위에서 언급한 것처럼 책에서 다음과 같은 문자을 볼 때는 성의 없는 표현이라고 넘어갔습니다.
앞뒤 상황에 따라서 행렬의 shape을 적당히 맞춰준다.
결과적으로 이 표현은 매우 적합한 표현입니다. 선형대수로 표현된 수식을 개별 요소로 분해하여 처리하는 것은 비효율적이며, 행렬 자체로 수식을 전계 하는 것이 맞습니다. 행렬을 적용하거나 최종 목적 행렬의 shape과 다를 경우에 행렬을 전치하여 shape을 맞추면 됩니다.
행렬의 Shape이 변경되는 유형은 크게 두 가지 인 것 같습니다.
행렬 곱: Weight Sum처럼 $\sum$을 이용하여 합산하는 것을 행렬곱으로 처리하는 경우
Case 1: Weight Sum - $\sum_j\sum_i w_jix_i = WX$
Case 2: L2 Norm - $||X||_2 = \sum x_i^2 = X^TX$
목적 행렬의 Shape
목적 행렬의 Shape에 현재 행렬의 Shape을 맞춤
결과적으로 앞뒤 상황에 따라서 행렬의 shape을 적당히 맞춰는 과정입니다.
결론: 수학에 대한 이미지
수학적 감각이 떨어지는 수포자로서, 이 문제를 고민하면서 두 가지를 느꼈습니다.
수학의 수식은 복잡한 개념은 단순화 시키고 커뮤니케이션하기 위한 표기법이다.
단순화 시키는 과정에서 대수학과 선형대수가 사용된다.
초기에 “내가 행렬의 방향을 이해하지 못하는 것은 미분을 잘 몰라서이며, 미분에 행렬의 방향을 결정하는 무엇인가가 있을 것이다.“라는 생각은 잘못된 것이었습니다. 행렬 변환은 식을 단순하게 만들기 위해서 선형대수화하는 과정에서 만들어진 것이었습니다.
수식에 대한 행렬의 변환에 확신이 없을 경우, 개별 요소로 수식 유도 후 행렬로 변환해 보면 명확할 것 같습니다.
이걸 이해하는데 두 달이 걸렸네요. 확실히 수학의 수식은 대화하고 개념을 단순화시키는 표기법인것 같습니다.