기계학습 자료에서 간혹 Norm과 관련된 수식이나 표기법을 나오면 당황스러울 때가 있습니다.
선형대수에 익숙하지 않다면 Norm이 이상하게 보일 수 있습니다.
본 문서에서는 인공신공망과 기계학습 일고리즘에서 사용되는 Norm을 이해하는 것을 목표로 최소한도의 Norm 개념을 정리합니다.
일반적으로 딥러닝에서 네트워크의 Overfitting(과적합) 문제를 해결하는 방법으로 다음과 같은 3가지 방법을 제시합니다.
더 많은 데이터를 사용할 것
Cross Validation
Regularization
더 이상 학습 데이터를 추가할 수 없거나 학습 데이터를 늘려도 과적합 문제가 해결되지 않을 때에는 3번 Regularization을 사용해야 합니다. Regularization에서는 Lose 함수를 다음과 같이 변형하여 사용합니다.
$$
cost(W, b) = \frac{1}{m}\sum_i^m{L(\hat{y^i}, y^i)} + \lambda\frac{1}{2}||w||^2
$$
위 수식은 기존 Cost 함수에 L2 Regularization을 위한 새로운 항을 추가한 변형된 형태의 Cost 함수입니다.
여기서 Weight의 Regularization을 위해서 Weight의 L2 Norm을 새로운 항으로 추가하고 있습니다. 딥러닝의 Regularization, kNN 알고리즘, kmean 알고리즘 등에서 L1 Norm/L2 Norm을 사용합니다.
Norm
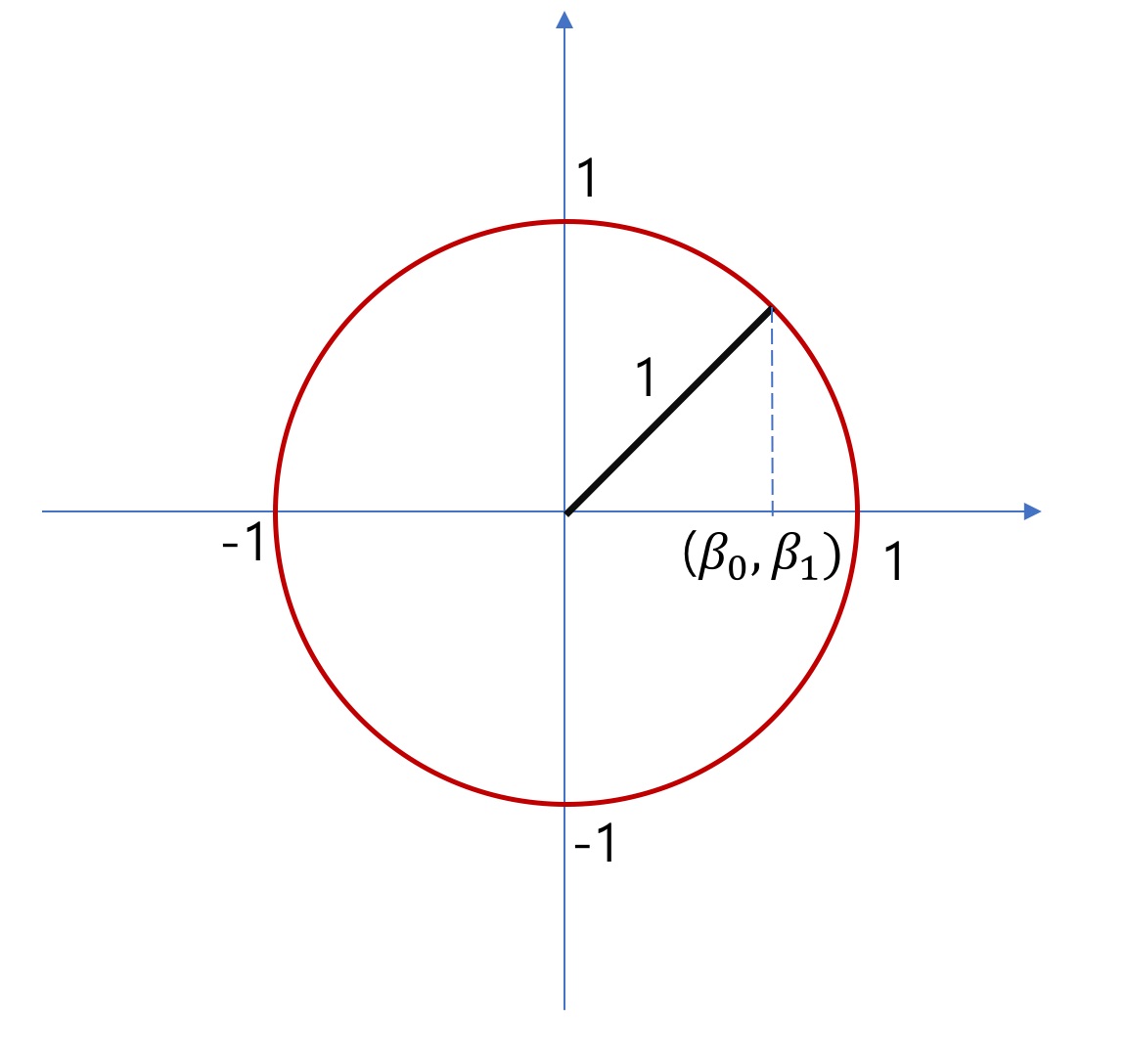
Norm은 벡터의 길이 혹은 크기를 측정하는 방법(함수)입니다. Norm이 측정한 벡터의 크기는 원점에서 벡터 좌표까지의 거리 혹은 Magnitude라고 합니다.
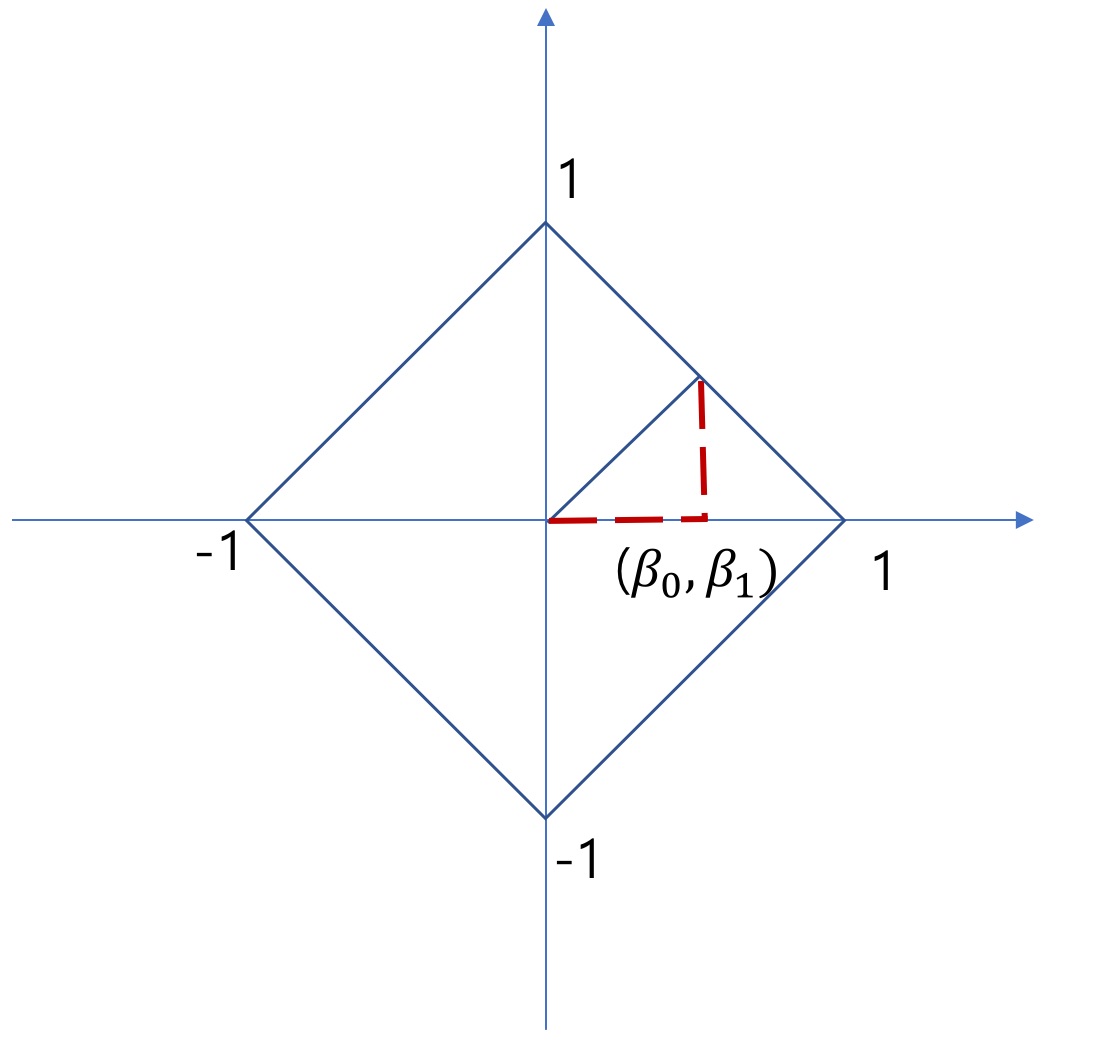
이 L1 Norm이 가능한 벡터는 다음과 같이 표현할 수 있습니다.
즉 벡터 B는 <그림 2>의 빨간색 마름모 선 위에 위치하게 됩니다.
마름모 선은 $|\beta_0| + |\beta_1|==1$인 벡터의 모음입니다.
그림 2:
유클리디안 공간(좌표 공간)에 표현한 B벡터의 $L_1 Norm$
일반적으로 가장 많이 사용되는 Norm은 L2 Norm입니다. 따라서 $||B||$와 같은 차수가 생략된 표기는 L2 Norm을 의미합니다.
Python Norm 구현
numpy는 norm 기능을 제공합니다. Numpy를 이용하여 L1 Norm과 L2 Norm을 구하는 방법을 소개합니다.
“numpy.linalg.norm” 함수를 이용하여 Norm을 차수에 맞게 바로 계산할 수 있습니다.
다음 예제에서는 3차원 벡터 5개를 포함하는 (5, 3) 행렬의 L1과 L2 Norm 계산 예제입니다 .