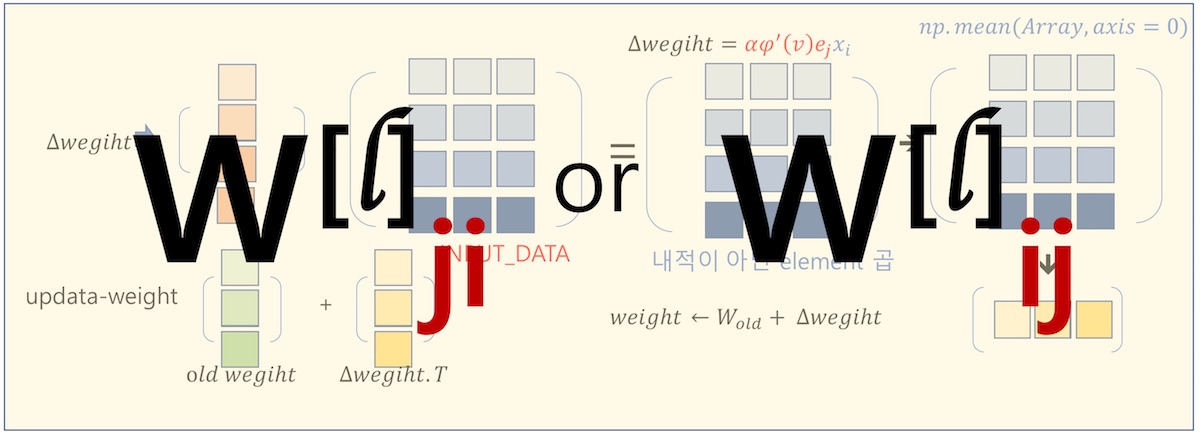
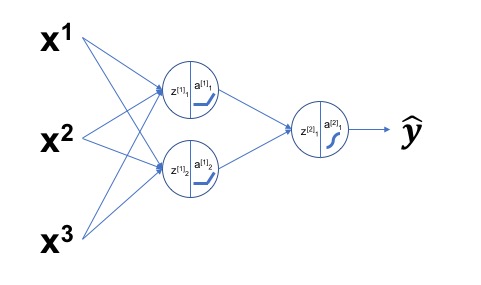
<식 1>의 (1)과 (2)는 다른 수식임에도 어떤 자료는 (1)과 같이 표현하고 어떤 자료는 (2)와 같이 표현합니다.
<식 1> 표기법의 각 요소는 다음과 정리할 수 있습니다.
$Z^{[l]}$: ‘l’번째 레이어의 Z(가중치 합, Weighted Sum) 벡터
$W^{[l]}$: ‘l’번째 레이어의 가중치 W 행렬
$A^{[l-1]}$: ‘l-1’번째 레이어의 출력 벡터, ‘l’번째 레이어의 입력 벡터
더욱 혼란스러운 것은 W 행렬의 요소를 표현하는 방식입니다. Coursera 등의 Andrew NG 교수님의 강의 자료를 보면 W 행렬의 각 요소를 $W^{[l]}_{ji}$ 로 표현합니다.
국내 여러 딥러닝 도서를 보면 W 행렬의 요소를 $W^{[l]}_{ij}로 표현합니다. 이러한 미묘한 차이에 따라서 Cost 함수 수식이나 Backpropagation 수식이 약간씩 달라지는 것 같고 상당히 혼란스러웠습니다.
딥러닝에 어느 정도 익숙해지면, 이러한 문제는 지엽적인 문제이기 때문에 크게 고려할 필요는 없습니다. 하지만 초기 입문자에게는 많은 혼란을 주는 첫 번째 시련의 시작점입니다. 본 문서에서는 $W{ji}$와 $W{ij}$의 의미와 이것이 어떤 영향을 주는지에 대하여 정리해 보겠습니다
0. 시작하기 전에: 용어 정의
표현이 혼동을 줄이기 위해서 W 행렬 표현 방식에 대하여 다음과 같이 명명하겠습니다.
W 행렬 요소를 $W_{ji}$로 표현하는 방법을 “ji 방식”으로 표현하겠습니다.
W 행렬 요소를 $W_{ij}$로 표현하는 방법을 “ij 방식”으로 표현하겠습니다.
1. 컬럼벡터와 열벡터
W 행렬을 “ji 방식” 혹은 “ij 방식”으로 관리하는 의미를 살펴보기 전에 데이터를 행렬로 처리하는 방식에 대하여 살펴보겠습니다.
딥러닝은 여러 개의 데이터를 행렬로 묶어서 한 번에 연산을 처리하는 방식을 좋아합니다. 이 방식을 사용함으로써 수식과 코드를 단순하게 유지할 수 있습니다. 또한, 행렬로 처리한 신경망을 GPU로 실행할 경우 연산 속도를 극단적으로 향상할 수있습니다.
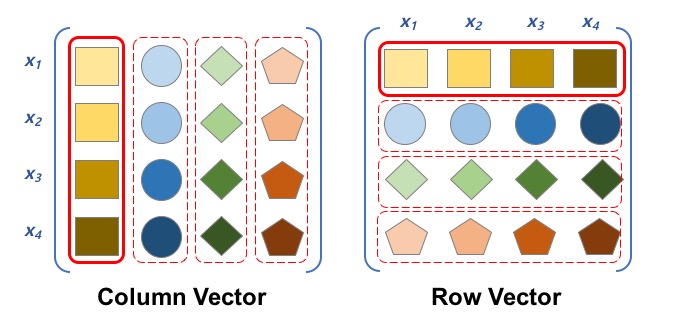
여러 데이터를 하나의 행렬로 나타내는 방식으로는 컬럼벡터 방식과 와 열벡터 방식이 있습니다.
예를 들어서, 한 개 입력 데이터가 4개 항목으로 구성된다면, 이 데이터를 벡터로 표현할 경우 4차원 벡터라고 합니다.
이 4차원 벡터를 한 개 “인스턴스“라고 합니다. 이 인스턴스를 행렬로 표현하는 방식에는 앞에서 언급한 컬럼벡터와 열백터가 있습니다.
그림 1:
컬럼벡터와 열벡터
<그림 1>의 첫 번째는 하나의 컬럼을 한 개의 인스턴스로 표현하는 컬럼벡터 방식 입니다. <그림 1>의 두 번째는 하나의 인스턴스를 열로 표현하는 열벡터 방식을 설명합니다.
관계형 데이터베이스는 열벡터 방식을 사용하는 대표적인 예입니다. 따라서 관계형 데이터베이스에 익숙한 일반적인 애플리케이션 개발자는 열벡터 방식이 더 친숙합니다. 그러나 기계학습(ML)에서는 열벡터보다는 컬럼벡터 방식을 더 선호합니다. 학습에 이용할 데이터는 컬럼벡터 방식으로 로딩하고 상요합니다.
1.1 ML 데이터 로딩:컬럼벡터
다음은 numpy를 이용하여 열벡터 방식으로 파일에 저장된 데이터를 컬럼벡터 방식으로 로딩하는 코드입니다.
아래 코드는 신경망에 학습시킬 데이터를 파일부터 로딩때 때 자주 사용됩니다.
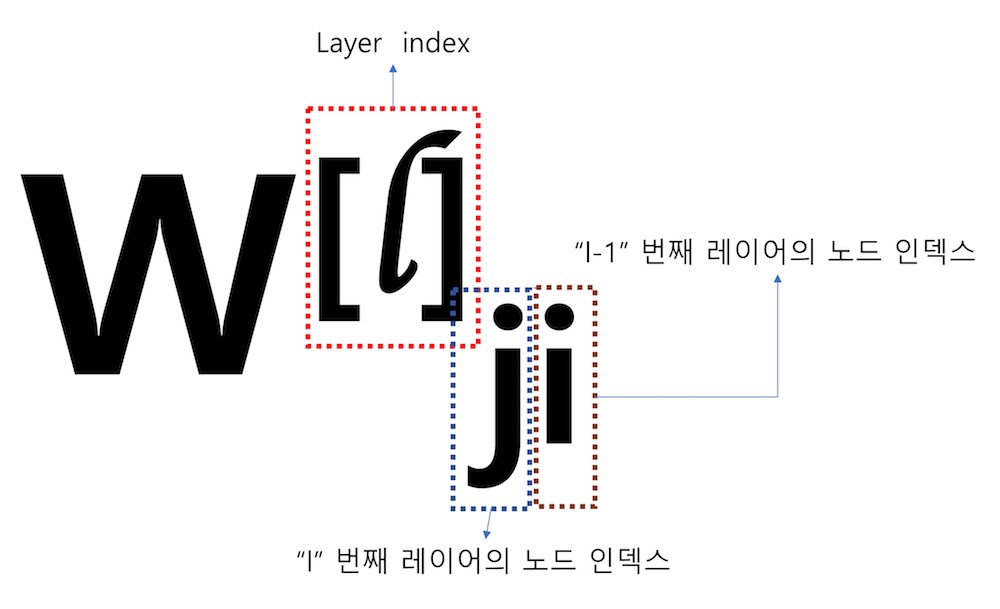
Andrew NG 교수님의 Coursera 강좌를 보면 각 레이어의 W 행렬의 요소를 <그림 2>와 표현합니다.
그림 2:
W 행렬의 요소 표기법
<그림 2>의 각 요소는 다음과 같이 정리할 수 있습니다.
l: W 행렬이 적용될 레이어 인덱스
j: l 계층의 노드 위치 인덱스
i: l-1 계층의 노드 위치 인덱스
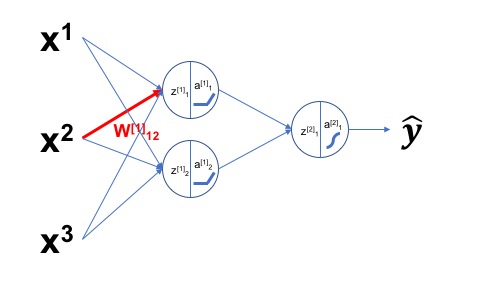
<그림 3>은 W 행렬 요소의 표기법 예제입니다. $W^{[1]}_{12}$는 <그림 3>의 빨간색으로 표기된 W 행렬 요소입니다. 이 표현은 다음과 같이 정리할 수 있습니다.
$W^{[1]}_{12}$: 첫 번째 레이어의 위치한 가중치 요소
출력 노드: 첫 번째 레이어(Layer 1)의 첫 번째 노드(j=1)
입력 데이터: 입력 레이어(Layer 0)의 두 번째 노드(i=2)
여기에서 “i”와 “j”는 두 가지 의미로 사용됩니다. 첫 번째 의미는 신경망의 W 행렬의 요소와 연관되는 관련 노드의 입력/출력 노드 정보입니다. 두 번째 의미는 W 행렬에서 요소의 위치를 나타내는 정보입니다. 이렇게 관련 노드 정보와 W 행렬의 요소 위치를 지정하는 두 가지 의미를 모두 포함합니다. 알파벳 “i” 다음 문자가 “j” 입니다. “i”는 입력 레이어의 노드 번호를 j는 출력 레이어의 노드 번호를 나타내는 문자입니다. 또한 행렬의 관점에서 볼 때 W 행렬의 요소 위치를 나타내기도 합니다. $W^{[1]}_{12}$는 W 행렬 첫 번째 행의 두 번째 컬럼 요소를 의미합니다.
W 행렬의 위치 관점에서 ji/ij 방식은 다음과 같이 정리할 수 있습니다.
ji: j는 행 지정, i는 열 지정
ij: i는 행 지정, j는 열 지정
그림 3:
W 행렬의 요소 표기법
그러나 <그림 3>의 $W^{[1]}_{12}$는 다음과 같은 의미를 담고 있습니다.
표현방식
표기법
의미
ji 방식
$W^{[1]}_{12}$
Layer (l-1)의 두번째 노드의 입력에 적용할 가중치이며 저장은 Layer l의 첫 번째 노드
ji 방식은 어딘지 조금 이상합니다. 표기법의 숫자(1)는 앞 표시가 다음 레이어의 노드 위치를 나태나고, 두 번째 숫자(2)는 앞 레이어의 노드 위치를 나타냅니다. 이 방식은 왠지 앞뒤가 바꾼 느낌입니다. W 행렬을 표현할 때 “ji“보다는 “ij” 방식이 가 더 직관적입니다. “ij“로 W 행렬을 표현하면 더 이해하기 편합니다. 가령 “ij“를 사용할 경우 <그림 3>의 W 요소는 $W^{[1]}_{21}$로 표기할 수 있습니다. 이 표기법은 다음과 같이 해석할 수 있습니다.
표현방식
표기법
의미
ij 방식
$W^{[1]}_{21}$
Layer (l-1)의 두번째 노드의 입력에 적용할 가중치이며 저장은 Layer l의 첫 번째 노드
이 “ij” 방식은 시선의 흐름에 따라 데이터의 흐름을 직관적으로 이해할 수 있습니다.
그런데 Andrew NG 교수는 “ji” 방식을 사용합니다. Andrew NG 교수는 직관성이 떨어지는 “ji” 표기법을 사용할까요? Andrew NG 교수는 “ji” 표기법을 사용하지만, 국내 딥러닝 책 중에서 다수는 “ij” 표기법을 사용합니다. 왜 각기 다른 표현 방식을 사용할까요?
다음 절에서는 W 행렬의 “ji“와 “ij” 방식의 차이점과 영향에 대하여 살펴보겠습니다.
3. W 행렬의 인덱스: “ji“와 “ij“의 차이점
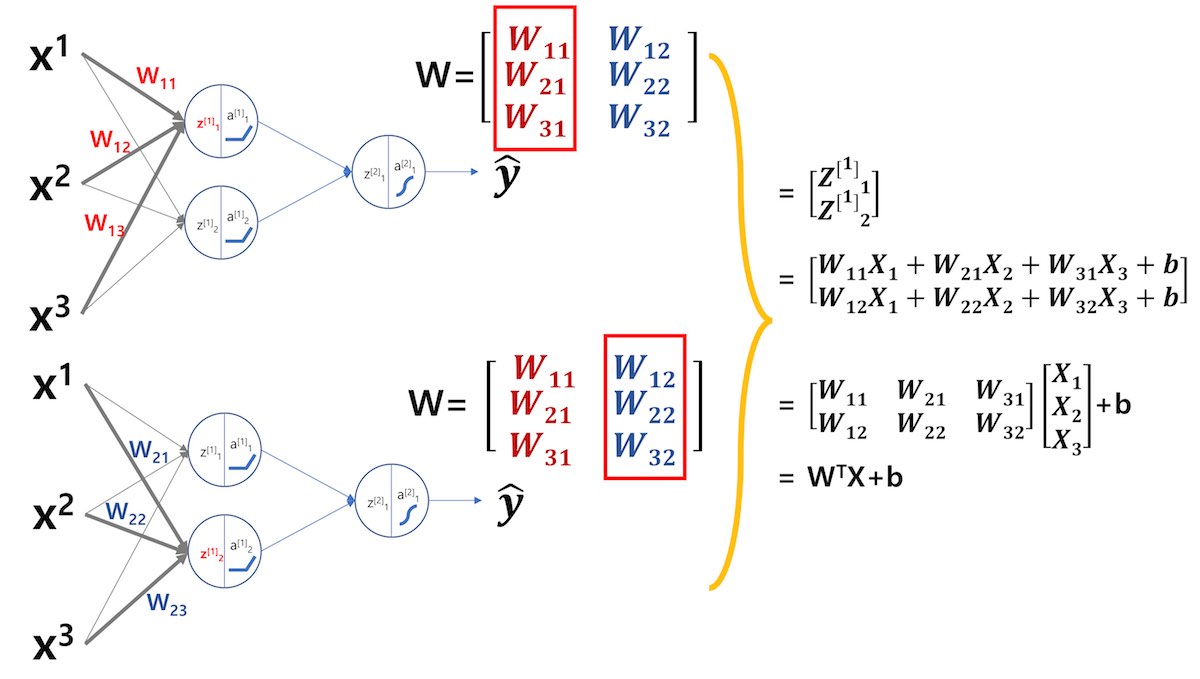
W 행렬을 “ji“와 “ij” 표기법으로 표현할 때 무엇이 달라지는지 확인하기 위해서 <그림 4>와 같은 단순한 네트워크의 W 행렬을 만들어 보겠습니다. <그림 4>의 첫 번째 레이어의 W 행렬을 표현할 때 입력 데이터(Input Feature)는 ㅓ컴컬럼벡터 방식을 사용합니다.
그림 4:
예제로 사용할 신경망
3.1 $W^{[l]}_{ij}$: “ij” 표기법 사용
아래와 같이 “ij” 표기법으로 W 행렬의 요소를 표현할 때, <그림 4>의 첫 번째 레이어 W 행렬을 정리해 보겠습니다.
여기서 “i”는 입력 레이어의 노드 번호이고 “j”는 출력 레이어의 데이터 저장 노드 번호입니다.
<수식 2> “ij” 방식 표현
$$W^{[l]}_{ij}$$
“ij” 방식으로 <그림 4>의 W 행렬을 정의하고 $Z^{[1]}$을 구하는 과정을 정리하면 <그림 5>와 같습니다.
그림 5:
ij 방식으로 W 행렬 정의
“ij” 표기법을 사용할 경우 W 행렬은 학습 데이터(X)와 같은 컬럼벡터 형태로 행렬이 만들어집니다. 따라서 학습 데이터와 W 행렬을 행렬곱하여 Weighted Sum인 $Z^{[1]}$을 만들기 위해서는 W 행렬을 전치(Transpose)해야 합니다.
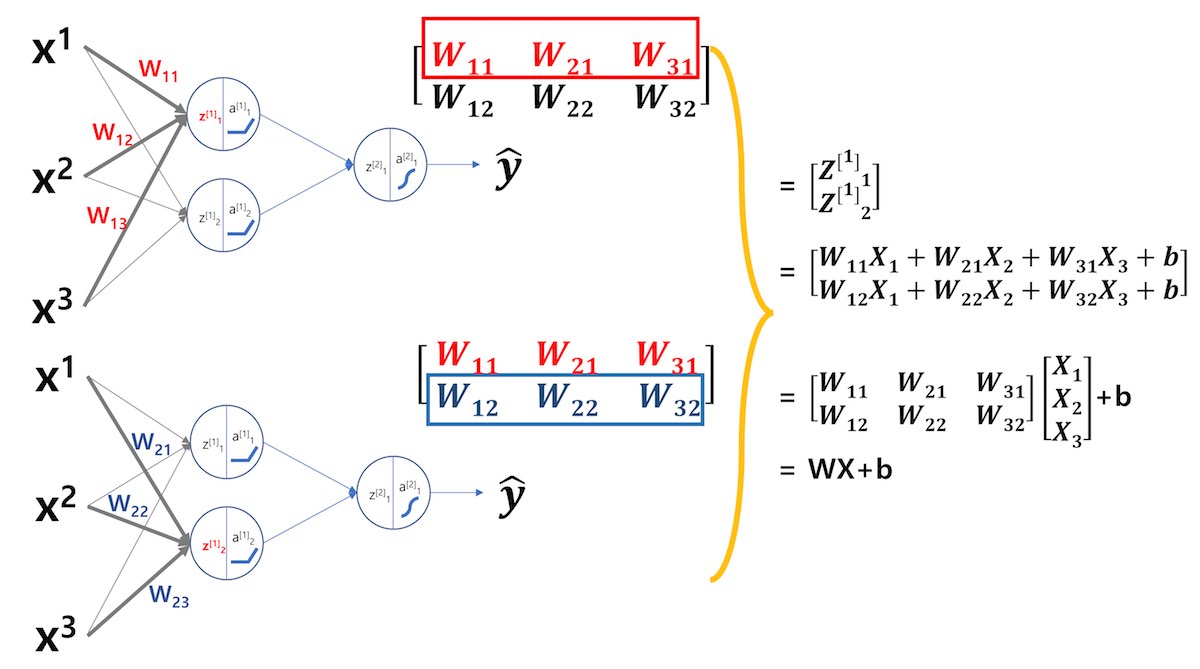
3.2 $W^{[l]}_{ji}$: “ji” 표기법 사용
이제 “ji” 방식으로 <그림 4>의 첫 번째 레이어 W 행렬 다시 표현해 보겠습니다.
<수식 3> “ji” 방식 표현
$$W^{[l]}_{ji}$$
“ji” 표기법으로 <그림 4>의 W 행렬을 정의하고 $Z^{[1]}$을 구하는 과정을 정리하면 <그림 6>과 같습니다.
그림 6:
ji 표기법으로 W 행렬 정의
“ji” 표기법을 사용할 경우 W 행렬은 열벡터 형태로 행렬이 만들어집니다. 따라서 학습 데이터와 W 행렬을 행렬곱하여 Weighted Sum인 $Z^{[1]}$을 만들 때, 행렬 변환 없이 바로 행렬곱을 할 수 있습니다.
4. W 행렬에 대한 “ji”와 “ij” 방식 사용시 주의 사항
“ji”와 “ij” 방식에 따라서 변경 점이 무엇인지 확인해 보겠습니다.
4.1 표기법에 따른 W 행렬의 Shape
위 <그림 5>와 <그림 6>에서 확인한 것 처럼, W 행렬에 대한 “ji“와 “ij” 방식에 따라서 W의 Shape이 다르게 만들어집니다.
j: “레이어 l”의 노드 인덱스
i: “레이어 l-1”의 노드 인덱스
$n_l$: “레이어 l-1”(출력 레이어)의 노드 수
$n_{l-1}$: “레이어 l”(입력 레이어)의 노드 수
“ij” 방식을 사용할 경우에 <그림 4> 신경망의 $W^{[l]}$의 Shape은 다음과 같이 만들어집니다.
<수식 5> “ij” 방식 사용 시 <그림 4> $W^{[l]}$ shape
$$
W^{[l]}의 shape = (n_{l-1}, n_l) = (3, 2)
$$
또한 “ji” 방식을 사용할 경우에 <그림 4> 신경망의 $W^{[l]}$의 Shape은 다음과 같습니다.
<수식 6> “ji” 방식 사용 시 <그림 4> $W^{[l]}$ shape
$$
W^{[l]}의 shape = (nl, n_{l-1}) = (2, 3)
$$
4.2 표기법에 따른 W의 전치
신경망에서 W의 표현 방식에 따라서 W 행렬의 Shape이 달라집니다. 이 Shape의 변화는 Z(Weighted Sum)을 구하는 수식과 Backpropagation의 $\Delta W$를 구하는 수식에 영향을 미칩니다.
Case 1. ij 방식 사용 시
ij 방식을 사용할 경우 forward propagation에서 Z를 계산할 때 W의 전치(transpose)가 발생합니다.
반면에 Backpropagation의 Hidden Layer의 오차 계산1에는 W를 전치할 필요가 없습니다.
앞에서 설명한 것처럼 W의 “ji“와 “ij” 표기법을 사용할 때 다음과 같은 부분을 주의해야 합니다.
W 행렬의 Shape 지정
Weighted Sum 계산 시 W 행렬의 전치
Hidden Layer의 오차 계산 시 W 행렬의 전치
주의할 사항 중에 1번은 신경망을 개발할 때, W 행렬을 초기화하는 과정에서 매우 중요한 요소입니다. 그러나 2와 3의 경우 Tensorflow, Keras, Pytorch 등 딥러닝 프레임워크를 사용할 경우 추상화된 부분입니다.
Andrew NG 교수의 강좌는 대부분 신경망의 이론적인 접근을 강조하고 있습니다. 이러한 이유로 Forward Propagation과 BackPropagation을 수식 중심으로 접근합니다. Andrew NG 교수님은 Forward Propagation의 수식을 단순하게 유지하려는 목적으로 W 행렬을 표현할 때 “ji” 방식을 사용한다고 생각합니다. “ji” 방식을 사용하기에 Andrew NG 교수님은 Forward Propagation을 다음과 같이 단순하게 정의합니다.
Tensorflow, Keras, Pytorch 등 모든 딥러닝 프레임워크는 W 행렬을 “ij” 방식을 선호하거나, W 행렬 자체를 추상화합니다.
Tensorflow는 W 행렬 정의 및 초기화에 $(n_{l-1}, n_l)$로 shape을 정의합니다.
$n_{l-1}$: 입력 레이어의 노드 수
$n_l$: 출력 레이어이 노드 수
Tensorflow에서 [그림 4]의 $W^{[1]}$ 행렬을 정의하고 초기화하면 코드는 다음가 같습니다.
# <코드 1> Tensorflow의 W 행렬 초기화 코드
import tensorlow as tf
W1 = tf.Variable(tf.random_uniform([3, 2], -1.0., 1.0.))
Tensorflow는 W 행렬을 “ij” 방식으로 표현하기 때문에, W의 Shape을 정의하는 코드가 직관적입니다.
keras는 W 자체를 추상화하여 개발자에게 노출되지 않습니다. 코드 상에서 ‘units’는 출력 레이어의 노드 수이고 ‘input_dims’는 입력 레이어의 노드 수입니다. keras는 W 행렬을 완전히 추상화하기 때문에 신경망을 직관적으로 이해하기 좋습니다.
# <코드 2> Keras의 W Shape 정의 코드: W 행렬이 추성화되어 있음
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(units=2, input_dim=3, activation='relu'))
7. 결론
W 행렬 표기법은 딥러닝을 처음 접할 때 굉장히 어렵게 느껴지는 부분입니다. 그러나 딥러닝 프레임워크를 사용한다면 W 행렬을 요소 단위로 접근하는 일은 거의 없습니다. 자료를 볼 때, W 행렬을 “ij“방식을 사용하느냐 “ji” 방식을 사용하느냐에 따라서 W 행렬의 Shape 정의와 Weight Sum 연산, Backpropagation의 은닉층 오차 연산 수식이 변화한다는 것을 이해하면 됩니다.
“ji” 방식을 사용할 경우 Forward Propagation을 단순하게 표기할 수 있습니다. 있다는 장점이 있습니다. 반면 W 행렬의 각 요소와 행렬의 Shape을 직관적으로 이해하기 어렵다는 단점이 있습니다. (사실 금방 익숙해집니다.)
“ij” 방식을 사용할 경우 W 행렬의 요소와 Shape을 더 직관적으로 표기할 수 있습니다. 반면에 Forward Propagation에 W 행렬을 전치하고, Backpropagation에서 W 행렬을 전치해야 하기 때문에 약간 복잡하게 느껴집니다. 이러한 복잡도는 딥러닝 프레임워크를 사용할 경우, 프레임워크가 전부 내부적으로 처리하기 때문에 코드 작성가가 직접 관여할 문제는 아닙니다.
이 차이점을 이해한다면 “ji“와 “ij” 방식의 표기법의 혼동을 최소화 할 수 있습니다. 이런 이유로 개념 파악과 이론을 중시하는 강좌에서는 “ji” 방식을 사용하고, 코드의 가독성을 높여야 하는 딥러닝 프레임워크에서는 “ij” 방식을 사용합니다.