[Handson_ML]ch02: ML 프로젝트 처음부터 끝까지
머신러닝 프로제트 절차
머신러닝 프로제트 절차
- 문제 정의
- 데이터 수집
- Data Discovery: 탐색과 시각화 for Insight
- 데이터 전처리
- 모델 선택 및 훈련
- 모델 미세 조정
- 해법(Solution) 제시
- 시스템 구축 및 모니터링, 유지보수
Dataset
주요 데이터 공개 사이트
- UC 얼바인: http://archive.ics.uci.edu/ml
- Kaggle: http://www.kaggle.com/datasets
- AWS: http://aws.amazon.com/ko/datasets
- meta potal site
- 인기 데이터셋 목록
California Housing Price
- 원본: http://lib.stat.cmu.edu/datasets/
- 카네기 멜론 통계학과에서 운영하는 사이트
- 수정본: http://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.html
- 원본: http://lib.stat.cmu.edu/datasets/
머신러닝 프로젝트 체크리스트 (Appendix. B)
- 머신러닝 프로젝트 주요 단계 (8개)
- 문제 정의 및 큰 그림 그리기
- 데이터 수집
- 통찰을 위해 데이터 탐색
- 데이터에 내지된 패턴을 머신러닝 알고리즘으로 잘 드러내도록 데이터 준비
- 여러 모델 적용 및 가장 좋은 몇 개 선택
- 모델 세밀하게 튜닝
- 솔루션 출시
- 시스템 런팅, 모니터링, 유지보수
문제 정의
- 목표를 비지니스 용어로 정의
- 이 솔루션을 어떻게 사용할 것인가?
- 현재 솔루션이 있다면 차선택은 무엇이 있는가?
- 문제 유형 정의
- 지도/비지도
- 온라인/오프라인
- 성능 측정 방법 정의
- 선능 지표가 비지니스 목표와 연결되어 있는가?
- 성능 지표의 검증
- 비지니스 목표와 비교하여 합당한지 확인
- 비지니스 목표를 도달하기 위해 필요한 최소한의 성능을 얼마인가?
- 비슷한 문제가 있나? 이전 방식이나 도구를 재사용할 수 있나?
- 해당 분야의 전문가가 있나?
- 도메인 지식을 지원 받을 인력 파악
- 수동으로 문제를 해결하는 방법은 무엇인가?
- 도메인 지식 확보
- 여러 사람이 세운 가정 나열
- 가능하다는 가정 검증
1) 문제 정의 단계
- 문제를 정확하게 파악하기 위한 작업
- 문제 정의
- 타입
- 성능 측정 방법
- 선능 지표 거증
- 성능 요구사항 정의
- 도메인 지식 확보
- 기존 처리 방법 확인
- 도메인 지식 확보 가능한가?
- 가정 나열 및 검증
2) 데이터 수집
- 필요한 데이터와 양을 나열
- 데이터 획득 가능한 Source 찾아 나열
- 필요한 데이터 사이즈 확인
- 법률과 라이센스 문제 확인 및 해결
- 접근 권한 획득
- 작업 환경 구성 (Data Lake, DB, Server)
- 데이터 수집
- 데이터 전처리, 원본은 유지 - 조작하기 편리한 상태로 뱐환
- 민감 데이터 삭제, 보호 검증 (개인정보 비식별화)
- 데이터의 크기와 타입을 확인
- 시계열
- 표본
- 지리 정보
- 데스트 데이터 분리하여 보호 - 데이터 유출에 각별히 조심
3) Data Discovery: 데이터 탐색
- 데이터 복사본 생성
- Sampling하여 적절한 크기를 사용
- Jupyter Notebook 사용
- Feature의 특성을 조사
- 이름
- 타입
- 범주형
- 정수/부동소수
- 최댓값/최솟값
- 누락된 값의 비율
- 잡음 정도와 잡음의 종류
- 확률적, 이상치, 반올림 에러 등
- 유용성 여부 체크
- 분포 형태: 가우시안, 균동, 로그
- 지도 학습이라면 타깃 속성 구분
- 데이터 시각화
- 특성간 상관관계 조사
- 수동으로 문제 해결할 수 있는 방법을 확인
- 적용 가능한 변환 찾음
- 필요한 경우 추가 데이터 확인
- 조사한 내용 기록
4) 데이터 준비: 전처리
- 데이터 작업은 복사본으로 작업
- 모든 변환은 함수로 작성 -> 전체적으로 재사용성 및 새로운 데이터셋에 적용이 쉽도록
- 다음 변환 작업을 용이하게
- 다음 프로젝트에 재사용
- 테스트셋에 동일하게 적용
- 솔루션 서비스 적용 후 새로운 데이터셋에 변환 용이하게
- 하이터파라미터로 적용
데이터 전처리 절차
- 데이터 정제
- 이상치 제거
- 누락된 값 채우기 - 0, 평균, 중간값
- 행, 열 제거
- 특성 선택(Optional)
- 특성 공학
- 연속 특성 이산화하기
- 특성 분해(범주형, 날짜/시간)
- 특성 변환(log, sqrt)
- 특성 조합으로 새로운 특성 만들기
- 특성 스케일 조정: 표준화, 정규화
5) 모델 선택
- selection {Linear Model, Naive-base, SVM, Random Forrest, Neural Network}
- 특정 성능 비교
- 가중 두드러빈 변수를 분석
- 모델이 만드는 에러 분석
- 이런 오류를 피하는 도메인 지식 파악
- 특성 선택과 특성 공학
- 여기까지 1-2회 반복
- 대표적인 알고리즘 3-5개 선택
6. 정밀 튜닝
- 모델 변환도 하이퍼파라미터로 관리할 것
- Missing Value 변환
- 탐색할 하이퍼파라미터가 많다면 그리드서치보다는 랜덤 서치를 사용 ㅜㅍ효
- 교차 검증을 통해서 정밀 튜닝
- 앙상블 시도해 볼것
- 최정 모델에 확신한 후에 일반화 오차를 추정하기 위해서 테스트셋을 실행
- 일반화 오차를 특정한 후에는 모델을 변경하지 말것.
- 일반화 오차 츠겅후 모델 변경하는 테스트셋에 과대적합
7. 솔루션 출시
- 문서화
- 솔루션이 어떻게 비지니스 목표에 달성했는지 설명(설득)
- 과정에서 발견한 인사이트를 소개
- 성공한것 그렇지 못한것
- 신기했던 것
- 가정과 시스템 한계
- 시각화로 내용 전달
- 중간 소득이 주택 가격에 대한 가장 중요한 예측 변수
8. 시스템 런칭
- 성능을 일정 간겨으로 확인
- 성능 감소시 알림을 받는 방법 적용
- 성능 감소는 지속적으로 느리게 발생할 수 있음
- 클라우드 소싱도 적극적으로 사용
- 입력 데이터의 품질 모니터링
- 온라인 학습일 경우 매우 중요
문제 정의
분석의 목적을 파악해야 한다.
- 모델 만들기가 최종 목표가 아니다.
- 분석의 목적이 무엇인지를 파악해야 한다.
대상 모델의 출력은 다른 신호(sigmal)과 함께 다른 머신러닝이 입력이 된다.
- 중간 주택 가격에 대한 예측
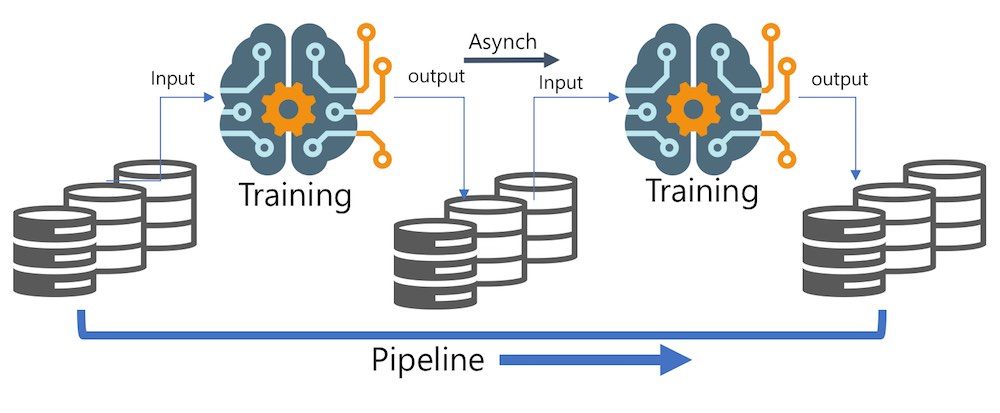
- 필수 질문
- 현재 솔루션은 어떻게 구성되어 있나요?
- 문제 해결에 대한 근거
- 참고 성능으로 사용 (baseline)
- 시나리오
- AS-IS: 팀이 구역 정보 수집, 중간 주택 가격이 없을 경우, 복잡한 규칙을 사용
- TO-BE: 구역 데이터를 기반으로 중간 주택 가격을 예측하는 모델 훈련
- 현재 솔루션은 어떻게 구성되어 있나요?
- 문제 정의로 부터 설계
- 지도 유형
- 지도학습
- 비지도학습
- 강화학습
- 학습 타입
- 배치
- 온라인
- 지도 유형
성능 지표 선택
(Self Question)성능 지표를 왜 선택해야 하는가?
- 모델을 학습시킬때 수 많은 버전이 만들어 짐
- 모델의 선택 기준이 필요
RMSE
- Root Mean Square Error
- $RMSE(X, h) = \sqrt{\frac{1}{m}\sum(h(X^{(i)})-y^{(i)})^2}$
MAE
- Mean Absolute Error
- $MAE(X, h) = \frac{1}{m}\sum(|h(X^{(i)})-y^{(i)})|)$
- 이상치가 많은 경우에 사용
Norm 요약 정리
RMSE는 L2 Norm
노름의 지수가 클수록 큰 값의 원소에 치우치며 작은 값을 무시
- RMSE가 MAE보다 이상치에 대한 영향이 큼
- 이상치가 많치 않을 경우 MAE보다 RMSE가 많이 사용됨
성능 지표 선택
- Hypothesis에 대한 공유
- 시나리오 체크 포인트
- 하위 시스템에 입력 변수는 카테고리
- 저렴/보통/고가
- 정확한 값이 필요 없음
- 현재 시스템은 회귀 문제가 아닌 분류 문제임
