CNN과 같은 이미지 데이터를 다룰 때 입력 데이터로 4차원 텐서를 다룹니다. 이 4차원 데이터는 (image 수, channel 수, Height , Width)와 같은 구조를 갖습니다. 데이터를 전처리하는 과정에서 Channel First인 텐서를 Channel Last 텐서로 변형해야 하는 상황이 발생했습니다. 처음에 4차원 구조는 상상하기도 어려운데 4차원 텐서를 전치하라는 것은 어떤 의미인지 난감했습니다.
문제의 시작: Channel First를 Channel Last로 변환
파이토치로 CIFAR10 데이터셋을 읽어와서 대상 이미지를 Mathplotlib의 plt.imshow() 함수로 출력하는 작업을 진행했습니다.
# 변환기 파이프라인 transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])# CIFAR10 데이터셋 로딩 및 변환trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform)# 미니배치 처리를 위한 데이터로더 생성trainloader=torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=2)dataiter=iter(trainloader)#첫번째 그룹 4개 이미지 데이터 획득train,label=dataiter.next()# 첫번째 4개 이미지의 데이터 Shape 확인print(train.shape)
출력:
torch.Size([4,3,32,32])
위 코드로 데이터의 첫 번째 그룹을 획득하고, 데이터의 Shape을 확인했습니다. 획득한 데이터의 Shape은 [4, 3, 32, 32]입니다.
Shape 정보로부터 현재 획득한 데이터는 4차원의 구조를 가지며, 4개 이미지가 각각 3개의 채널을 가집니다. 그리고 이미지 크기가 32X32라는 것을 파악할 수 있습니다.
현재 데이터는 이미지의 채널 정보가 앞에 위치하는 Channel First 형태입니다. plt.imshow()는 이미지를 출력하는 함수입니다. 이 함수는 Channel Last 형태의 이미지 데이터만을 지원합니다. 따라서 Channel First을 Channel Last 포멧으로 변경해야 했습니다.
위 코드의 transpose 함수는 다차원 텐서을 변형(Transpose)하는 작업을 수행합니다. train_t의 shape을 확인해 보면 채널이 마지막으로 이동한 것을 확인할 수 있습니다.
그러나 이 코드에서 사용된 다차원 행렬이 어떻게 전치되는지를 직관적으로 이해하기란 상당히 어렵습니다. 이 문서에서는 다차원 행렬을 전치한다는 것이 어떤 의미가 있고 어떻게 수행하는가에 대하여 정리해 보겠습니다.
텐서의 Shape & Reshape
다차원 행렬인 텐서의 Transpose를 다루기 전에 Shape과 Reshape이 무엇인지 알아보겠습니다.
머신러닝에서 데이터의 형태를 기준으로 다음과 같이 분류합니다.
스칼라(Scala): 0 차원 텐서
배열(Array): 1 차원 텐서
행렬(Matrix): 2 차원 텐서
텐서(Tensor): N 차원 텐서
Shape
Shape을 통해서 텐서의 구조를 파악할 수 있습니다.
Shape 예제
분류
설명
샘플
(8,)
1차원 텐서
배열 형태로 8개의 요소로 구성되어 있음
[1 2 3 4 5 6 7 8]
(2,4)
2차원 텐서
두 개 그룹으로 나누고 각 그룹은 4개의 요소를 갖고 있는 구조
[[1, 2, 3, 4], [5, 6, 7, 8]]
(2,2,2)
3차원 텐서
2개의 구룹으로 나누고, 각 그롭 별로 각각 4개의 요소로 2개 그룹으로 분할 됨
[ [ [1, 2], [3, 4] ], [ [5, 6], [7, 8] ] ]
이와 같은 데이터가 어떤 형태를 보이는지 설명하는 방식이 Shape입니다. Shape을 통해서 몇 개의 데이터가 어떤 구조로 구조화되어 있는지 파악할 수 있습니다.
텐서는 배열을 구성하는 요소를 구분하는 구조를 만들고, 그곳에 요소를 할당한 것으로 생각할 수 있습니다. 여기서 요소를 구분하는 구조가 바로 Shape입니다.
Reshape
Reshape은 특정 데이터의 구조를 변경하는 작업입니다. np.reshpae 함수로 구현되어 있습니다. 기존 데이터의 구조를 변경하는 작업입니다. 여기서 데이터 구조가 변경될 뿐, 데이터의 순서는 변경되지 않습니다.
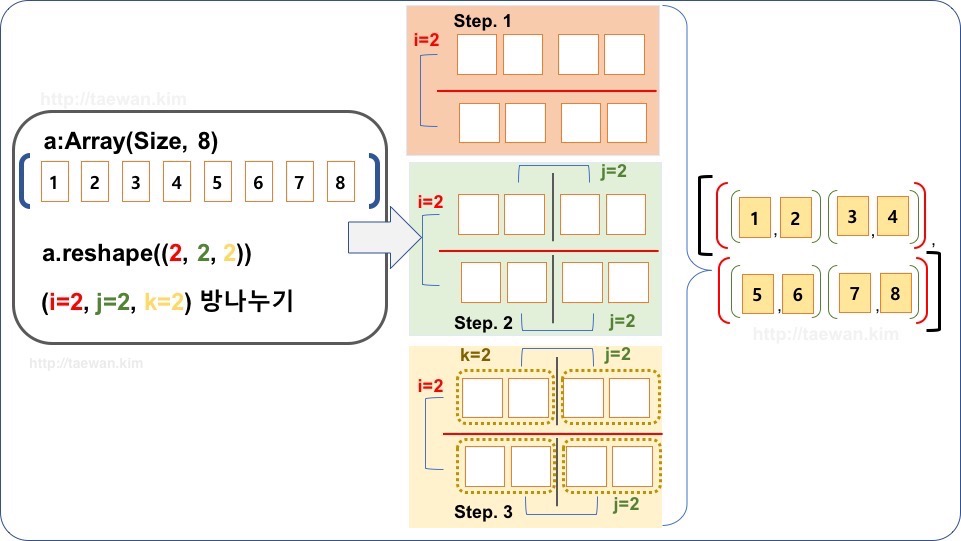
그림 1:
reshape 예제
<그림 1>은 배열을 행렬로 행렬을 텐서로 변환하는 예제입니다. 데이터가 분할되는 구조는 변경되지만, 데이터의 배열 순서는 변경되지 않는 것을 확인할 수 있습니다.
요약하면 Reshape(np.reshape)은 데이터의 배치 순서는 변경하지 않고 데이터를 구분하는 블록 구조를 변경하는 작업입니다.
행렬 전치(Matrix Transpose)
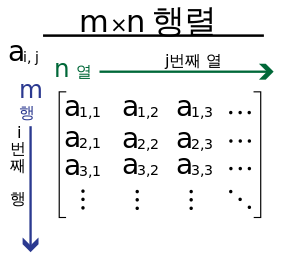
선형대수에서 행렬의 전치란 행과 연을 교환하여 새로운 행렬을 얻는 것입니다. 2차원 행렬은 <그림 2>와 같이 행을 의미하는 i와 열을 의미하는 j로 나타냅니다.
그림 2:
행렬의 요소 위치
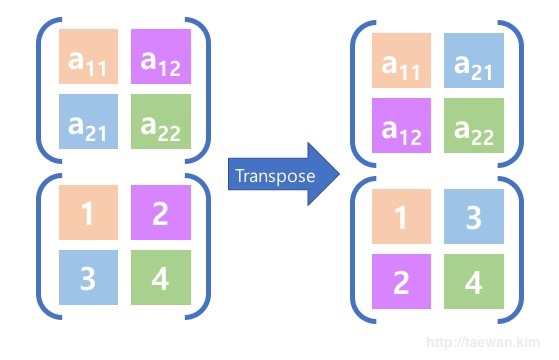
2차원 행렬을 전치(Transpose)할 경우 요소의 i와 j를 뒤바꿔 새로운 위치로 요소를 이동시킵니다. <그림 3>과 같이 행렬의 각 요소는 i와 j의 위치를 바뀐 새로운 자리로 이동합니다. 이때 i와 j가 같은 대각선의 요소는 i와 j를 교환해도 같은 위치를 나타내기 때문에 기존 위치를 유지합니다.
그림 3:
2차원 행렬의 전치
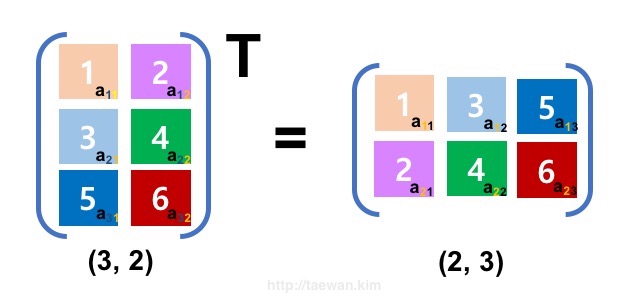
이렇게 행렬의 전치(Transpose)를 수행하면 요소의 위치가 변경됩니다. 다음 <그림 4>는 Shape이 (2, 3)인 2차원 행렬을 전치시킨 결과입니다. 정사각 행렬이 아닌 행렬의 경우 Shape과 요소의 위치가 모두 변경됩니다.
그림 4:
2차원 행렬의 전치, Shape 변경
N차원 텐서의 전치
텐서의 전치는 행렬의 위치를 나타내는 인덱스 순열 중 하나의 기준으로 요소의 위치를 변경하는 일련의 과정입니다.
<그림 4>의 2차원 행렬에서 요소의 위치를 나타내는 인덱스는 i와 j였습니다. i와 j의 순열은 총 2가지이며, 현재 인덱스 형태를 제외하면 1개만 남습니다.1 즉 전치에 따른 요소 이동의 기준은 (j, i) 1개 뿐입니다. 행렬의 전치의 기준이 되는 인덱스 형태는 (j, i) 1개뿐입니다. 결과적으로 2차원 행렬의 전치는 i와 j를 뒤바꾼 (j, i)를 기준으로 요소의 위치를 변경하는 것이 전부입니다.
3차원 텐서부터는 전치가 간단하지 않습니다. 3차원 텐서의 경우 요소의 위치를 결정하는 인덱스는 i, j, k 3개로 구성됩니다. 3개 인덱스의 순열 수는 총 (3!)입니다. 즉 순열 수는 총 6개이며, 현재 인덱스를 제외하면 5가지 유형의 인덱스가 만들어집니다. 현재 (i, j, k)를 제외하고 (i, k, j), (j, i, k), (j, k, i), (k, i, j), (k, j, i) 5개의 인덱스 형태를 기준으로 3차원 텐서는 전치할 수 있습니다.
이렇게 인덱스 순열의 형태에 따라서 Shape도 정의되고, 요소의 위치도 변경됩니다.
3차원 순열의 전치
그림 5:
3차원 텐서
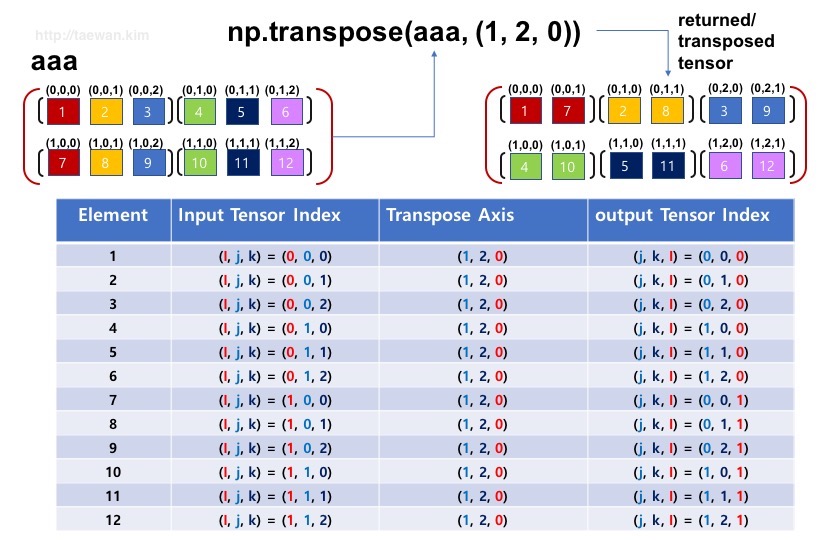
<그림 5>는 3차원 텐서를 준비하는 과정입니다. 12개의 요소로 Shape이 (2, 2, 3)인 3차원 텐서를 준비했습니다.
다차원 텐서의 전치는 numpy.transpose 함수로 처리됩니다. transpose 함수는 2개의 입력 파라미터를 취합니다. 첫 번째 파라미터는 전치할 대상 텐서 객체를 취하고, 두 번째 파라미터로는 전치의 기준이 되는 axis입니다. axis에는 튜플 형태로 전치의 기준을 설정합니다.
np.transpose(a,axes=None)
axis에는 두 가지 의미가 있습니다. 하나는 입력된 텐서(a)의 Shape을 변경하는 기준이며, 두 번째는 입력 텐서의 요소를 어떤 기준으로 이동시킬지를 결정하는 기준입니다. n 차원 텐서는 n개의 인덱스를 갖고 있습니다. n개의 인덱스를 순서대로 숫자로 지정했습니다. 첫 번째 인덱스는 0이고, 두 번째 인덱스는 1입니다. 마지막 n번째 인덱스는 (n-1)이 됩니다.
Shape 변환
Shape이 (2, 2, 3)인 텐서를 (1, 2, 0)으로 전치(Transpose)하면 새로운 텐서의 Shape은 (2, 3, 2) 형태로 변경됩니다. 0은 첫 번째 shape(a.shape[0]), 1은 두 번째 shape(a.shape1), 2는 세 번째 shape(a.shape[2])를 나타냅니다.
np.transpose(a,axes=(1,2,0))
위 코드는 a 텐서의 shape은 (a.shape[0], a.shape[1], a.shape[2]) 입니다. 이 shape을 axes 기준에 따라 (a.shape1, a.shape[2], a.shape[0])으로 변환합니다.
각 요소의 위치 이동
axis는 앞에서 설명한 인덱스별로 할당된 숫자로 전치의 기준이 되는 인덱스 조합 순서를 정의합니다. axis에 정의된 인덱스 순서로 요소의 위치를 변경합니다.
그림 6:
3차원 텐서, 기존 인덱스를 그대로 유지한 전치
<그림 6>에서 transpose 함수의 axex에 (0, 1, 2)를 입력했습니다. 이 axex 설정값은 기존 인덱스를 그대로 유지하겠다는 의미입니다. 따라서 (0, 1, 2)를 축으로 다차원 텐서를 전치하면, shape과 요소의 위치 같은 입력 텐서와 동일한 텐서가 반환됩니다.
그림 7:
3차원 텐서, (1, 2, 0)으로 전치
<그림 7>에서 transpose 함수의 axis에 (1, 2, 0)을 입력했습니다. 이 axex 설정값은 입력 텐서의 ijk에 요소를 출력 텐서의 jki 위치로 이동시킨다는 설정입니다.
그림 8:
3차원 텐서, (1, 2, 0)를 축으로 요소 위치 변화
<그림 7>의 텐서 변환은 <그림 8>과 같은 방식으로 입력 텐서의 요소를 이동시킵니다. 각 요소는 기존의 인덱스(ijk)를 axis에 설정된 순서로 변환하여, 새로운 텐서 구조의 새로운 위치로 이동하게 됩니다.
np.tranpose 함수의 axis 설정이 이해
다음은 CIFAR10 데이터 셋을 Pytorch로 로딩한 후, 첫 번째 데이터에 대한 Shape을 확인하느 코드입니다.
# CIFAR10 데이터셋 로딩 및 변환trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform)# 미니배치 처리를 위한 데이터로더 생성trainloader=torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=2)dataiter=iter(trainloader)#첫번째 그룹 4개 이미지 데이터 획득train,label=dataiter.next()# 첫번째 4개 이미지의 데이터 Shape 확인dataiter=iter(trainloader)train,test=dataiter.next()print('trains의 Shape: {}'.format(train.shape))
출력:
trains의 Shape: torch.Size([4, 3, 32, 32])
앞에서 설명한 것처럼 CIFAR10 데이터 셋은 4차원 텐서로 구성됩니디. 위 학습 데이터는 4장의 이미지, 이미지 별로 3개의 필터, 필터 별로 높이가 32 픽셀이고 폭이 32픽셀인 데이터 셋입니다. 특이한 점은 Channel First 포맷입니다. 이 데이터를 Matplotlib로 시각화하기 위해서 Channel First를 Channel Last로 변환해야 합니다. [4, 3, 32, 32]의 Shape을 [4, 32, 32, 3]의 형태로 변환해야 합니다.
학습 데이터의 포맷을 변경하기 위해서 tp.transpose 함수를 사용할 것이며, 입력 파라미터인 axis로 (0, 2, 3, 1)을 설정합니다. 이 함수를 실행하면 사진의 폭과 높이 앞에 존재하던 채널을 Shape의 마지막으로 옮겨집니다. 결과적으로 Channel Last 포맷으로 변환됩니다.
transpose 함수의 axis에 입력된 기준을 보면 (0, 2, 3, 1)을 입력한 것을 볼 수 있습니다. 첫 번째 Shape(이미지)은 그대로 유지하고 두 번째 채널을 마지막으로 돌리는 설정입니다. 기존의 (4, 3, 32, 32, )의 Shape을 (4, 32, 32, 3)으로 구조를 재조정하고 (i,j,k,l) 인덱스 요소를 (i,k,l,j)로 이동시키는 작업을 수행합니다.
요약
numpy를 사용하여 행렬 혹은 텐서를 전치(Transpose)하는 것이 어떤 의미인지를 확인해 보았습니다. 행렬의 전치란 지정한 축으로 텐서의 Shape을 변경하고, 새로운 Shape 구조에 맞도록 각 요소의 위치를 변경하는 과정입니다.
numpy의 transpose 함수는 n 차원 텐서를 전치시키는 기능을 제공합니다. 이 함수는 변환할 텐서와 변환 기준 축(axis)을 입력 매개변수로 갖습니다. axis는 shape과 인덱스의 순서를 숫자로 나타내는 튜플입니다.
numpy의 transpose 함수는 axis 튜플을 기준으로 텐서의 shape을 변경하고, axis 튜플을 기준으로 요소의 인덱스를 변경하고 재배치합니다.