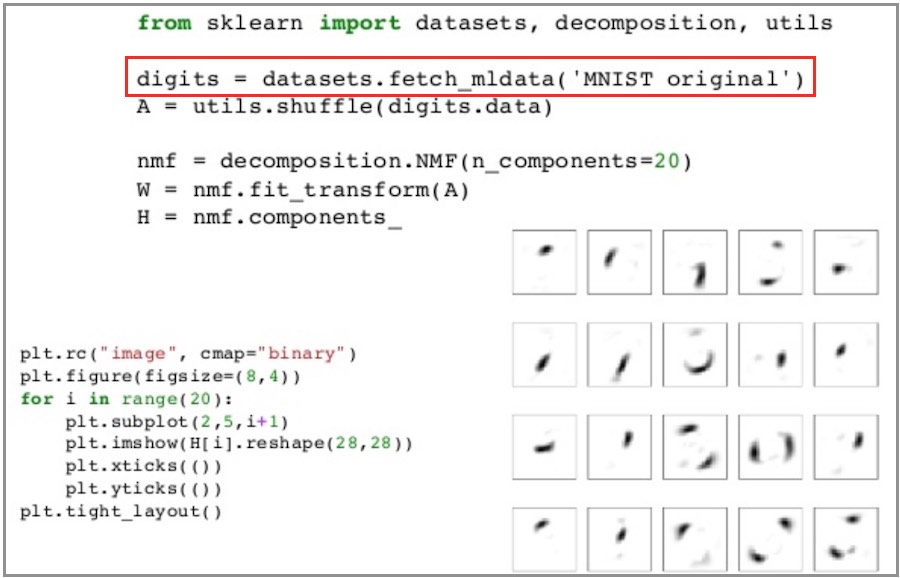
scikit-learn은 테스트 데이터로 사용할 수 있는 여러 데이터셋를 간편하게 로딩하는 기능을 제공합니다. 특히 머신러닝 테스트에 사용할 수 있는 대표적인 데이터셋을 로딩하는 기능을 제공하기 때문에, 이 기능을 이용하여 많은 문서가 이용하여 입문자 문서를 작성하는 것이 일반적입니다.
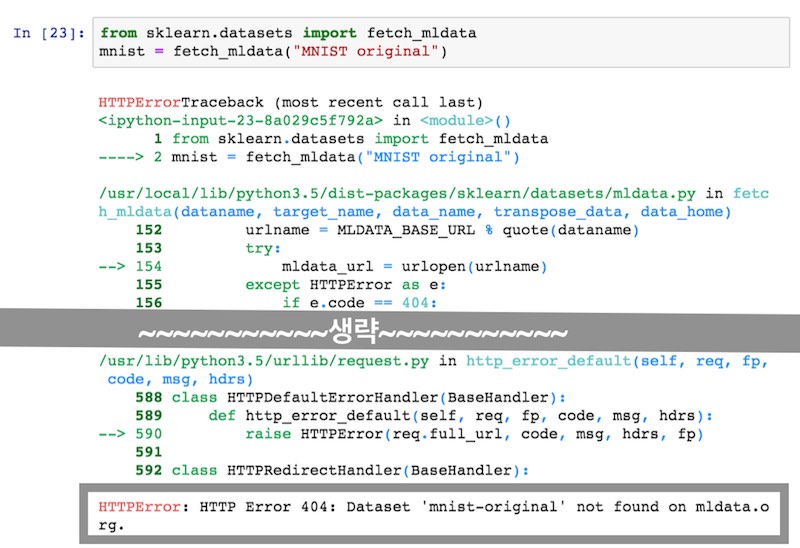
scikit-learn이 제공하는 데이터셋 로딩 기능 중에서 fetch_mldata 함수는 mldata.org의 데이터셋을 이용합니다. 최근에 mldata.org 사이트가 장애가 발생하면서 이 함수는 정상적으로 작동하지 않습니다. 이 오류를 우회하는 방법을 정리합니다.
#Line 29
MLDATA_BASE_URL = "http://mldata.org/repository/data/download/matlab/%s"
def fetch_mldata(dataname, target_name='label', data_name='data',
transpose_data=True, data_home=None):
## 코드 생략
if not exists(data_home):
os.makedirs(data_home)
matlab_name = dataname + '.mat'
filename = join(data_home, matlab_name)
# if the file does not exist, download it
#Line 151
if not exists(filename):
urlname = MLDATA_BASE_URL % quote(dataname)
try:
mldata_url = urlopen(urlname)
except HTTPError as e:
if e.code == 404:
e.msg = "Dataset '%s' not found on mldata.org." % dataname
raise
# store Matlab file
try:
with open(filename, 'w+b') as matlab_file:
copyfileobj(mldata_url, matlab_file)
except:
os.remove(filename)
raise
mldata_url.close()
## 코드 생략
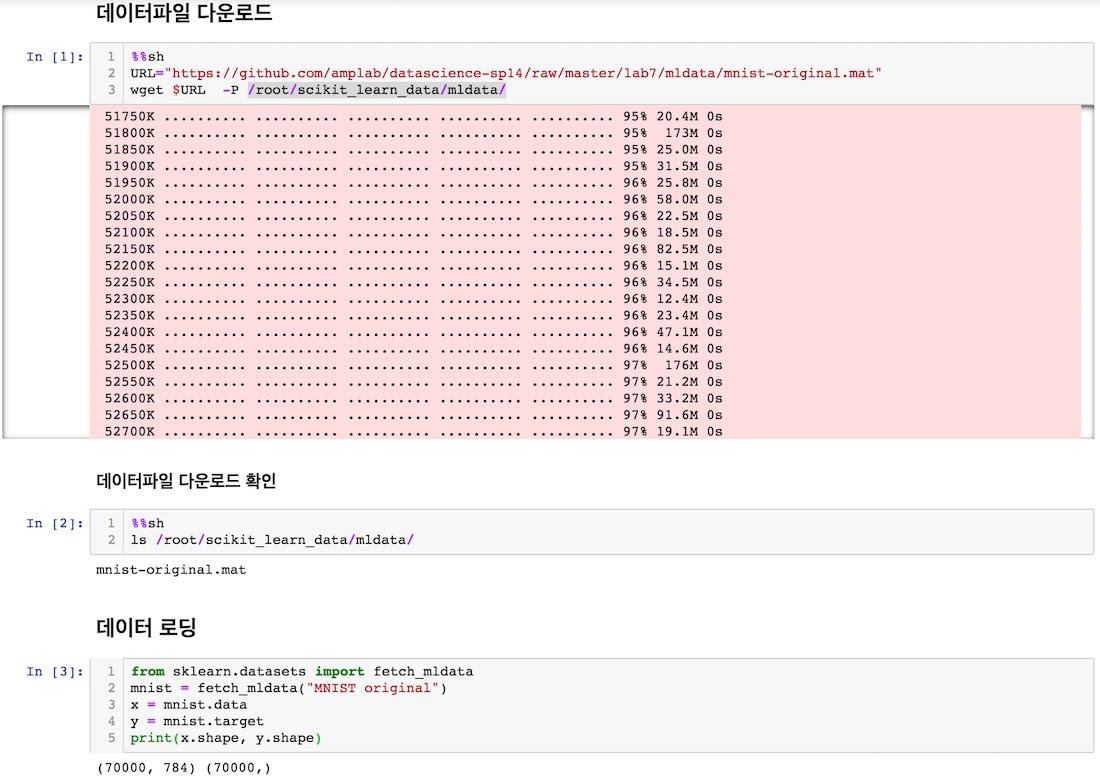
fetch_mldata 함수의 구현 부에서 151라인은 data_home 디렉터리에 데이터 파일(mat 파일1)이 없으면 MLDATA_BASE_URL에서 파일을 다운로드하도록 구현되어 있습니다.
fetch_mldata("MNIST original")은 matlab 파일 포맷인 mnist_original.mat 파일을 다운로드 하고 로딩하는 함수입니다. 이 함수를 실행할 때 오류가 발생하는 이유는 mnist_original.mat2 파일을 mldata.org에서 다운받을 수 없기 때문입니다.
오류 해결 방법
fetch_mldata("MNIST original") 실행 오류는 해결하는 방법은 다음과 같이 2가지가 있습니다.
data_home 디렉터리에 mnist_original.mat 다운로드한 다음에 함수 실행
mnist_original.mat 다운로드한 다음, data_home을 지정하여 함수 실행
두 방법 모두 mnist_original.dat 파일을 별도로 다운로드해야 합니다. mnist_original.dat 파일은 다음 URL에서 다운로드 할 수 있습니다.