머신러닝 용어: Example, Sample & Data Point
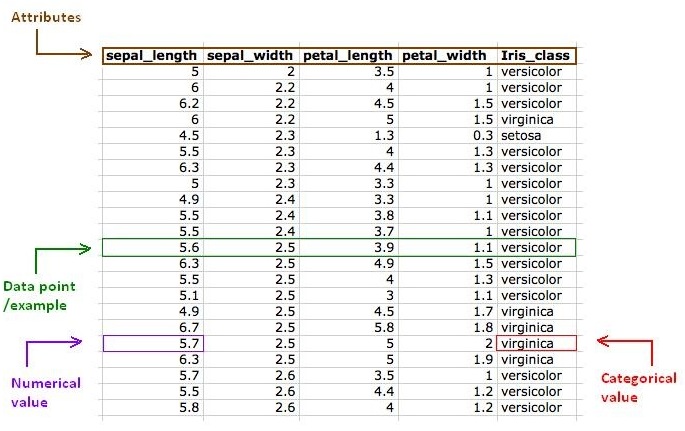
머신러닝을 공부하면서 굉장히 생소하게 느껴졌던 용어가 몇 개 있습니다. 그 중에서 가장 어색했던 용어는 데이터셋의 개별 데이터를 표현하는 용어였습니다. 일반적으로 머신러닝 데이터셋의 개별 데이터를 다음과 같은 용어로 표현합니다.
- Example
- Sample
- Instance
- Data Point
문서를 번역하거나 정리하는 과정에서 위 용어를 어떻게 처리해야 할지가 항상 고민이었습니다. 개별 데이터를 왜 이렇게 표현하는지 제 개인적인 느낌을 정리해 보겠습니다.
Example과 Sample
The MNIST database of handwritten digits, available from this page, has a training set of 60,000 examples, and a test set of 10,000 examples.
위와 같은 표현에서 개별 데이터를 표현할 때, Example과 Sample이란 용어를 사용합니다. 이 문장을 번역할 때, 학습 데이터셋은 데이터 6 만건으로 해석했습니다. 처음에는 몇 건의 데이터가 아니라 Example과 Sample을 사용하는 어감이 상당히 어색했습니다.
머신러닝을 위해서 수집한 데이터는 일반적으로 과거의 경험입니다. 과거의 경험을 통해서 미지의 패턴과 경향을 인식하는 지식을 습득한 후, 새로운 데이터의 결과를 예측하는 것을 목표로 합니다. 이러한 의미에서 수집한 데이터셋은 과거의 경험입니다. 이런 배경으로 볼 때 Example 및 Sample에 적합한 한글 용어는 사례와 견본이라고 할 수 있습니다. 이 중에서 사례가 더 적당한 용어라고 생각합니다.
Instance
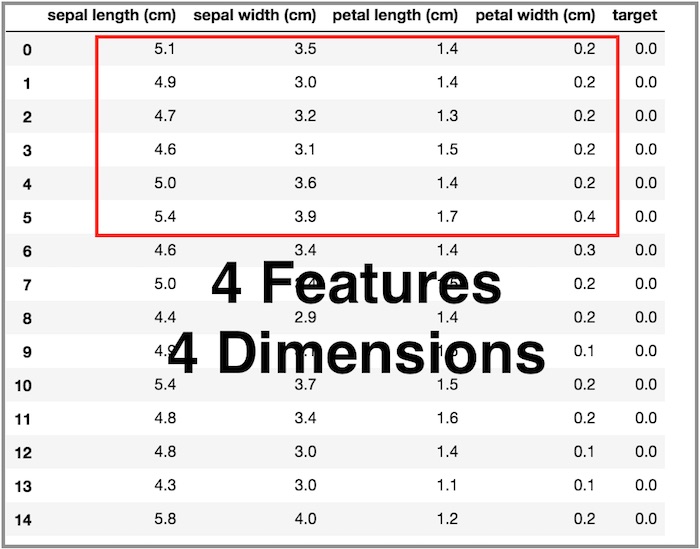
위 그림은 분류 예제 데이터로 자주 사용하는 IRIS(붓꽃) 데이터셋입니다. 붓꽃 데이터는 150개 사례(Example)의 데이터를 가지며, 각 사례는 4개의 특성을 갖습니다. 이렇게 머신러닝의 각 사례는 여러개의 특성으로 구성됩니다. 이처럼 데이터별로 여러 개의 속성을 가지며, 간 단위 데이터의 속성은 하나의 객체 혹은 인스턴스로 표현할 수 있습니다. 각 사례를 개별적인 특성을 갖는 단위로 묶을 수 있다는 의미에서 인스턴스라고 표현하기도 합니다.
Data Point
| 방갯수 | 면적 | 욕실갯수 |
|---|---|---|
| 2 | 100 | 1 |
| 3 | 84 | 2 |
| 4 | 96 | 2 |
위 데이터는 집의 특성을 나타내는 데이터셋입니다. 이 데이터셋은 3개의 특성(컬럼)을 가지며, 각 특성을 다음과 같이 벡터로 표현될 수 있습니다.
$$
\begin{align}
1^{st} example &= \begin{bmatrix}
2 \\
100 \\
1
\end{bmatrix} =(2, 100, 1)
\end{align}
$$
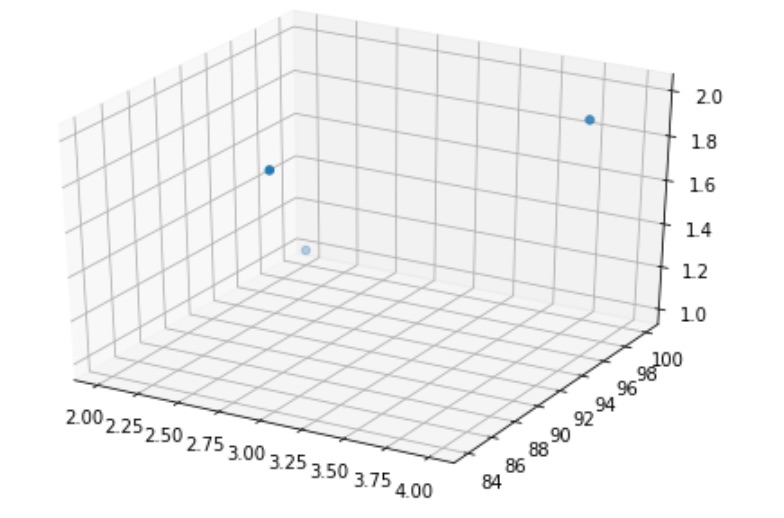
위 데이터셋의 3개 사례는 위와 같이 벡터로 표현될 수 있습니다. 이 벡터는 다음과 같은 3차원의 좌표 공간에 특정 위치로 표현될 수 있습니다. 이렇게 다차원 공간에 위치로 표현되는 벡터라는 의미에서 Data Point라는 용어를 사용합니다.
요약
머신러닝에 사용하는 데이터셋의 개별적인 데이터를 Example, Sample, Instance, Data Point라고 부릅니다. 이는 데이터의 성격이 과거 경험이라는 취지에서 사례와 견본이라는 이미지를 갖고 있습니다. 또한 여러개의 속성을 갖는다는 의미에서 인스턴스 그리고 벡터로 표현 될 수 있고, 다차원 공간에서 위치를 나타낼 수 있다는 의미에서 Data Point라고 부릅니다. 벡터의 형태에 따라서 컬럼 벡터 혹은 로(Raw) 벡터라고 부르기도 합니다.
