MLY:10. 개발 세트와 지표로 반복 속도 향상
- 원문제목: 10. Having a dev set and metric speeds up iterations
- 최종 업데이트: 2018년 06월 08일
- 목차이동: Machine Learning Yearning 목차
- 저자: Andrew NG
- 원문: http://www.mlyearning.org
- 분류: Setting up development and test sets
새로운 문제에 대하여 어떤 접근법이 가장 효과적인지를 미리 아는 것은 정말 어렵습니다. 기계 학습 전문 연구자 조차도 일반적으로 만족스러운 결과를 얻기 전에 수집가지 아이디어를 시도합니다. 기계 학습 시스템을 구축할 때 필자는 다음과 같은 절차로 작업을 수행합니다.
- 시스템 구축 방법에 대한 몇 가지 아이디어로 시작하십시오.
- 코드로 아이디어를 구현하십시오.
- 아이디어가 얼마나 잘하는지 실험해보십시오. (보통 처음 몇 가지 아이디어는 작동하지 않습니다!) 이러한 학습을 바탕으로 더 많은 아이디어를 만들어보고 반복적으로 적용해 보십시오.
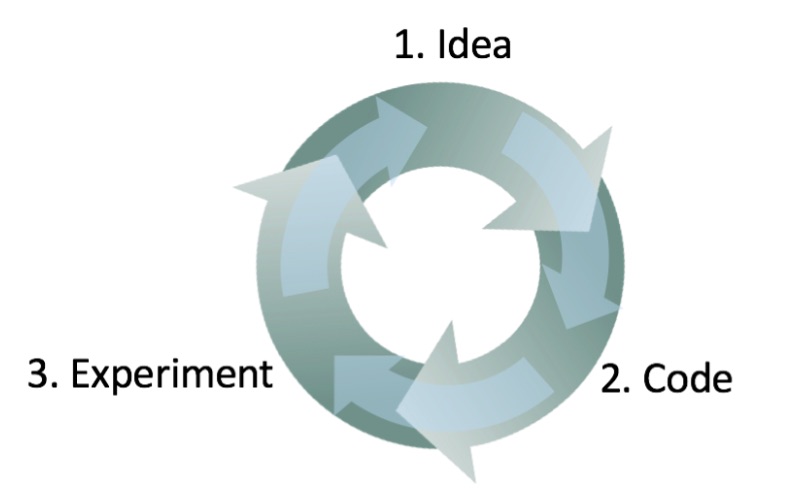
이런 접근법은 반복적인 프로세스입니다. 이 반복을 빠르게 진행할 수록, 전체적인 진행 속도는 더 빨리잡니다. 이것이 바로 개발 세트와 테스트 세트, 평가 지표가 중요한 이유입니다. 새로운 아이디어를 시도할 때마다, 개발 세트에서 이러한 새로운 시도의 성능을 측정하면, 올바른 방향으로 가고 있는지 신속하게 확인할 수 있습니다.
반대로 개발 세트 및 평가 지표가 없다고 가정 해보십시오. 새로운 고양이 분류기를 개발할 때마다, 새 분류기를 앱에 통합하고 몇 시간 동안 앱을 사용한 후, 새로운 분류기의 개선 여부를 파악해야합니다. 이것은 매우 느린 프로세스입니다. 또한 분류기의 정확도를 95.0%에서 95.1%로 향상하는 경우, 앱을 사용하는 것으로는 0.1% 향상을 감지하지 못할 수도 있습니다. 그러나 이러한 0.1% 개선 사항을 지속적으로 축적함으로써 시스템의 많은 발전이 이루어질 것입니다. 개발 세트 및 측정 항목을 사용하면 어떤 아이디어가 성공적으로 작은 (또는 큰) 개선을 제공하는지 신속하게 감지 할 수 있으므로 어떤 아이디어를 정제할 것인지, 어떤 아이디어를 제거할 것인지를 신속하게 결정할 수 있습니다.
이 문서는 Andrew NG 교수님께서 집필 중인 Machine Learning Yearning의 10장 번역입니다. 원제는 “10. Having a dev set and metric speeds up iterations” 입니다. 원문 Ebook은 http://www.mlyearning.org 에서 구독할 수 있습니다.
