MLY:04. 스케일이 기계학습의 발전를 이끈다.
- 원문제목: 4. Scale drives machine learning progress
- 최종 업데이트: 2018년 06월 04일
- 목차이동: Machine Learning Yearning 목차
- 저자: Andrew NG
- 원문: http://www.mlyearning.org
- 분류: Intro
딥러닝(신경망)에 대한 대부분의 개념은 수집 년 동안 계속되어 왔습니다. 왜 이 아이디어가 지금 뜨는 걸까요??
최근 발전을 이끈 가장 중요한 두 가지 요인은 다음과 같습니다.
- 데이터 가용성(Data availability): 사람들은 이제 디지털 장비(랩톱, 모바일 장치)와 많은 시간을 보내고 있습니다. 사람들의 디지털 활동은 많은 양의 데이터를 생산합니다. 그리고 이 데이터는 학습 알고리즘에 제공됩니다.
- 연산 규모(Computational Scale): 지금 우리가 가지고 있는 거대한 데이터셋을 충분히 활용할 수 있는 신경망을 훈련하는 것이 불과 몇 년 전에 가능해 졌습니다.
자세히 말하자면, 더 많은 데이터를 축적하더라도, 일반적으로 로지스틱 회귀와 같은 오래된 학습 알고리즘 성능에는 고원과 같은 양상을 보입니다. 즉, 학습 곡선이 “평평해지고” 알고리즘에 더 많은 데이터를 제공해도 성능이 향상되지 않습니다.
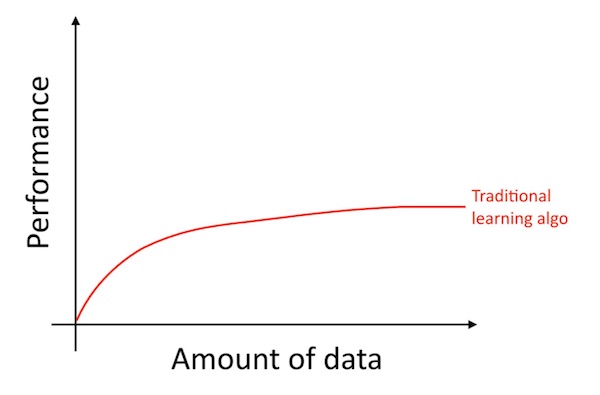
이러한 현상은 마치 오래된 알고리즘이 현재 확보한 데이터로 무엇을 해야할지 모르는 것과같은 모습입니다.
동일한 지도학습 문제를 작은 신경망으로 학습시면, 조금 더 향상된 성능을 얻을 수 있을겁니다.
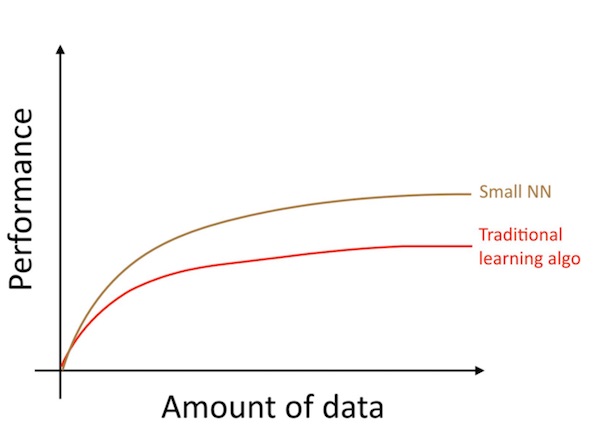
여기에서 “작은 NN”이란 작은 수은 은닉 단위/층/파라미터 만을 갖는 신경망을 의미합니다. 마지막으로 더 큰 크기의 신경망을 학습시키면 더 좋은 성능을 얻을 수 있습니다.1
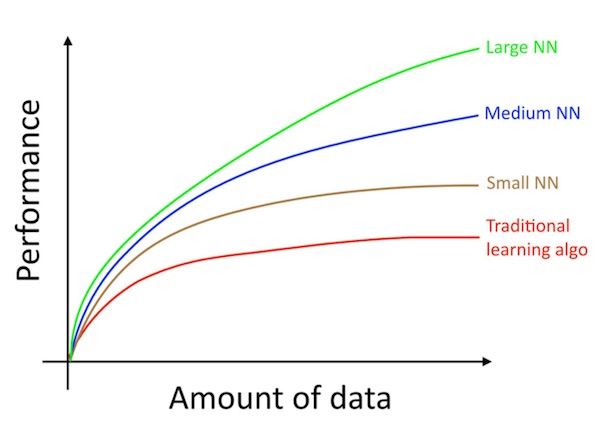
따라서 (i)매우 큰 신경망을 훈련할 때 최고의 성능을 얻을 수 있습니다. 위의 녹색 곡선이 되기 위해서는, (ii)엄청난 양의 데이터가 필요합니다.
신경망 구조와 같은 많은 다른 세부 사항들도 중요합니다. 그리고 여기서 많은 혁신이 있었습니다. 그러나 오늘날 알고리즘의 성능을 향상시키는 가장 안정적인 방법의 하나는 여전히 더 큰 네트워크를 학습시키고 더 많은 데이터를 사용하는 것입니다.
(i)과 (ii)를 성공하는 방법은 놀랍도록 복잡합니다. 이 책에서는 자세한 내용을 설명합니다. 우리는 전통적인 학습 알고리즘과 신경망 모두에 유용한 일반적인 전략부터 시작하여 심층 학습 시스템 구축을 위한 가장 현대적인 전략까지도 수립 해 볼 것입니다.
이 문서는 Andrew NG 교수님께서 집필 중인 Machine Learning Yearning의 4장 번역입니다. 원제는 “4. Scale drives machine learning progress” 입니다. 원문 Ebook은 http://www.mlyearning.org [↗NW] 에서 내려받을 수 있습니다.
- 이 다이아그램은 작은 데이터셋 범위에서 NN이 더 좋은 성능을 보이는 것처럼 보입니다. 이는 방대한 데이터셋의 범위에서 NN이 더 잘 작동한다는 것과 일관성이 떨어집니다. 작은 데이터 규모에서는 피처의 수작업 가공 정도에 따라서, 전통적인 알고리즘이 더 좋을 성능을 보일 수도 있고 아닐 수도 있습니다. 예를 들어서, 20개의 학습 데이터가 있으면, 로지스틱 회귀와 신경망 중에서 어떤 것을 사용할 것인가는 중요하지 않을 수도 있습니다. 피처의 수작업 처리가 알고리즘 선택보다 더 큰 영향을 미칩니다. 그러나 데이터셋이 백만 건이라면, 주저 없이 신경망을 선택할 것입니다. [return]
