[20180707]'파이썬 라이브러리를 활용한 머신러닝' 1장
1장에서는 머신러닝의 기본 개념과 Scikit-learn에 대한 간략한 소개로 시작합니다. 또한 이 책에서 다룰 주요 환경에 대해 소개합니다. 마지막으로 KNN으로 붓꽃을 분류하는 예제를 통해서 데이터 수집, 적재, 탐색 및 학습의 과정을 소개합니다. 머신러닝의 가장 기본적인 용어와 접근법에 대한 기초적인 이해를 전달하는 것을 목표로합니다.
1장의 예제 코드와 실행 결과는 다음 URL에서 확인할 수 있습니다. - https://github.com/taewanme/notebooks4til/blob/master/MLWithPythonLibraries/ch01.ipynb
1장 구성
전에 26페이지 정도 분량으로 기계학습이란 무엇이고 이 책에서 다루는 환경에 대하여 소개합니다. 붓꽃을 분류하는 첫 번째 예제로 간단한 지도학습을 진행하는 방식을 소개합니다. 전체 목차는 다음과 같습니다.
- 1.1 왜 머신러닝인가?
- 1.2 왜 파이썬인가?
- 1.3 sckkit-learn
- 1.4 필수 라이브러리
- 1.5 파이썬2 vs 파이썬3
- 1.6 이 책에서 사용하는 소프트웨어 버전
- 1.7 첫 번째 애플리케이션 붓꽃의 품종 분류
- 데이터 적재
- 상관관계 측정: 훈련 데이터와 테스트 데이터
- 데이터 탐색
- KNN 학습 및 예측
- 모델 평가
- 1.8 요약
핵심 요약
머신러닝의 의미
- 머신러닝이란 데이터에서 지식을 출하는 작업이다.
- 사용할 데이터를 이해하고 그 데이터가 해결해야 할 문제와 어떤 관련이 있는지를 이해가 시작점이다.
프로그래밍 기반 인공지능
- 개발을 기반으로 하는 규칙기반 전문가 시스템(과거)
- 개발이 쉽다는 장점이 있지만 많은 단점과 한계가 존재
- 단점
- 결정에 필요한 로직은 한 분야나 직업에 국한
- 규칙 변경 시 재개발이 필요함
- 규칙 설계 시 해당 분야 전문가의 결정 방식에 대한 높은 이해가 필요
- 한계
- 인위적으로 규칙을 파악하기 어려운 문제
- 이미지 인식, 음성 인식에 적용 어려움
- 단점
기계학습 유형
- 지도 학습
- 알려진 사실을 바탕으로 일반화된 모델을 만들어 의사 결정 프로세스를 자동화하는 것
- 알고리즘에 입력과 기대 출력을 제공하여 입력과 출력의 대응 관계 도출
- 입력과 기대 출력 값을 만드는 과정이 어려움
- 알고리즘 도출 과정은 자동화
- 결과에 대한 성능 측정이 쉽다는 것 강점
- 사용 사례
- 편지봉투 손글씨 판별
- 의료 영상 종양 판단
- 카드 부정 거래 감지
- 비지도 학습
- 입력만을 제공
- 데이터의 관계 파악에 사용
- 사용 사례
- 블로그 주제 구분
- 비슷한 성향의 고객을 그룹으로 묶기
- 비정상 웹 사이트 접근 탐지
기계학습 과정에 필요한 질문
기계학습의 정확한 의미 파악과 올바른 진행을 위해서 필요한 질문, 기계학습 과정에서 지속적으로 점검해야 함
- 어떤 질문에 대한 답을 원하는가?
- 가지고 있는 데이터로부터 원하는 답을 찾을 수 있는가?
- 내 질문을 기계학습의 문제로 가장 잘 기술하는 방법은 무엇인가?
- 문제를 풀기 위한 충분한 데이터를 얻었는가?
- 내가 추출한 데이터의 특성은 무엇이며 좋은 예측을 만들어 낼 수 있을 것인가?
- 기계학습 애플리케이션이 성과를 어떻게 측정할 것인가?
- 기계학습 솔루션이 다른 연구나 제품과 어떻게 협력할 수 있는가?
주요 용어 정리
- 1개의 입력 데이터
- 샘플, Sample
- 인스턴스, Instance
- Data Point
- Row
- 1개 데이터 속의 컬럼
- 속성: Feature
- 좋은 데이터 확보 방안
- feature extraction: 특성 추출
- feature engineering: 특성 공학
예제: 붓꽃 분류
붓꽃 데이터 적재
from sklearn.datasets import load_iris
iris_dataset = load_iris()
print(iris_dataset['data'].shape)
(150, 4)
과적합 방지을 위한 학습과 테스트 데이터 분할
- 학습 데이터, 학습 셋
- 테스트 데이터, 테스트 셋, 홀드-아웃 셋(Hold-out set)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
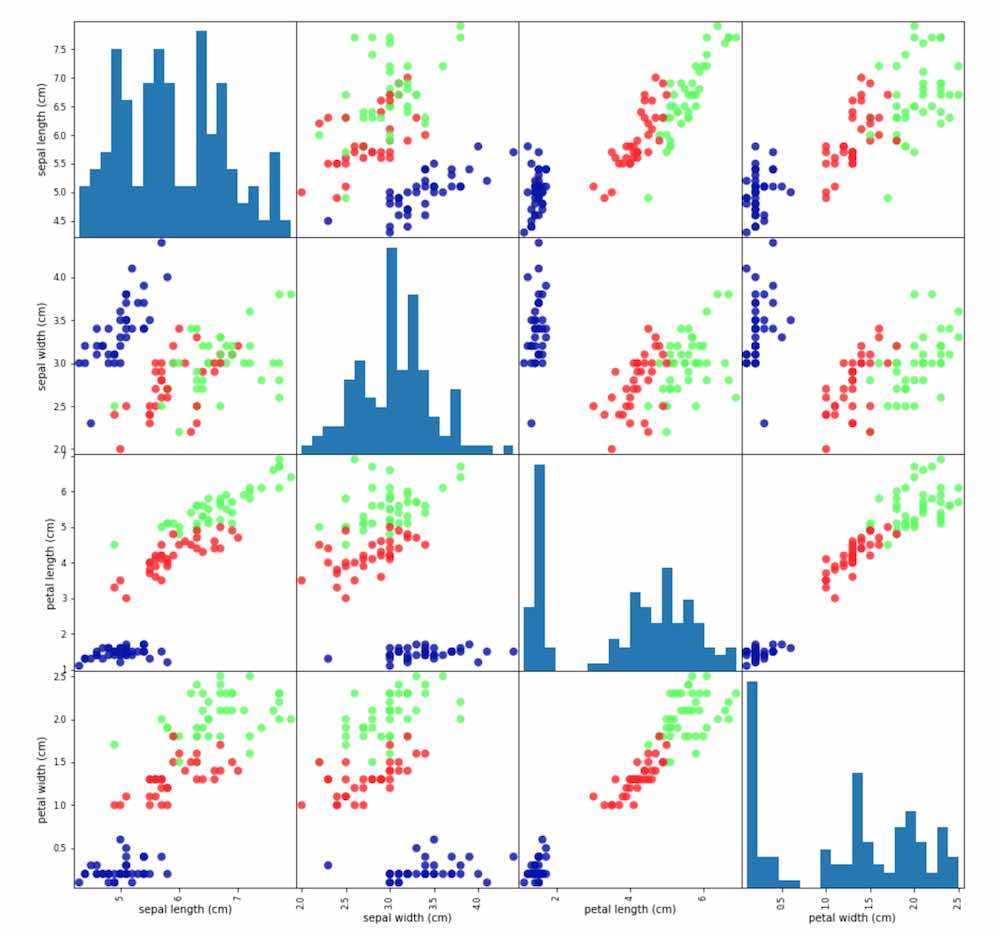
데이터 탐색
- scatter matrix를 이용한 데이터 탐색
- scatter matrix로 특성의 데이터 분포와 특성 간의 경향성 파악
import mglearn
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
KNN 학습
- 1개의 근접 데이터를 파악하고 그 레이블 값(목적 값)을 입력데이터의 출력 값으로 결정하는 알고리즘
- 유사도에 대한 고찰
- KNN: K-nearest neighbors (K-최근접 이웃)
- 입력데이터와 유사한 k개의 데이터를 구하고, 그 K개 데이터의 분류 중 가장 빈도가 높은 클래스를 입력 데이터의 분류로 결정하는 알고리즘
- Scikit Learn에서는 KNeighborsClassifier로 구현됨
- Estimator 클래스 상속
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
KNN 새로운 데이터에 대하 예측
- 예측 레이블 값으로 실제 클래스 명 Lookup
X_new = np.array([[5, 2.9, 1, 0.2]])
prediction = knn.predict(X_new)
print("테스트 세트의 정확도: {}".format(
iris_dataset['target_names'][prediction]))
'테스트 세트의 정확도: 0.97'
모델 평가
y_pred = knn.predict(X_test)
np.mean(y_pred == y_test)
knn.score(X_test, y_test)
요약
기계학습에 대한 기본적인 소개와 전체적인 데이터 분석 절차에 대한 대략적인 흐름을 설명합니다. scikit-learn을 한번 돌려보고 경험할 수 있습니다. 기계학습 입문자에게 꼭 필요한 내용입니다. 가장 중요하게 생각되는 부분은 기계학습을 진행하면서 고민해야 할 7개 질문입니다.
