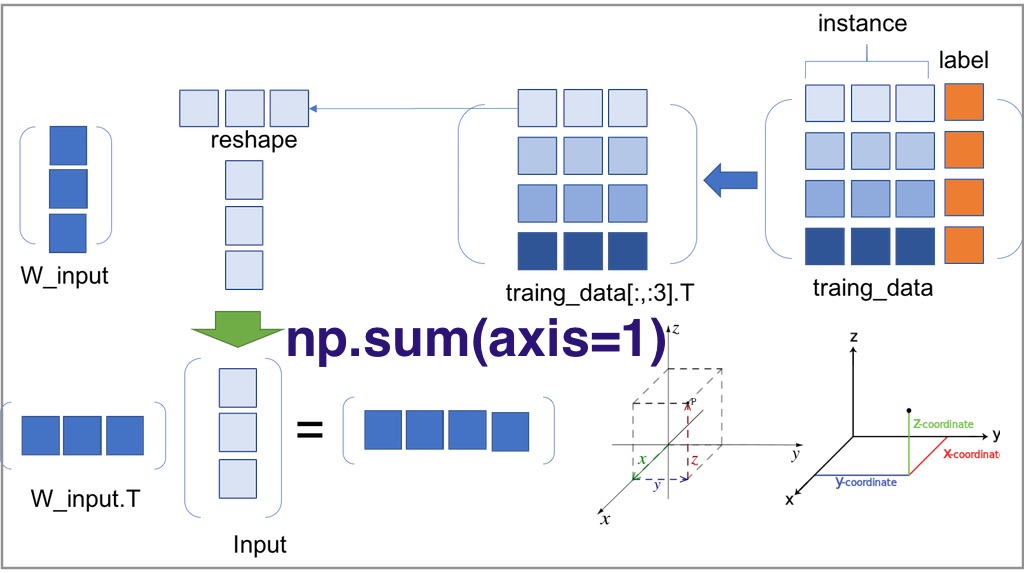
통계 및 데이터 분석, 딥러닝을 하다 보면 스칼라, 벡터, 행렬, 텐서와 같은 다양한 데이터 유형을 다루게 됩니다. 데이터 분석은 여러 유형의 데이터 합을 구하고 빈도수와 확률을 계산하는 반복적인 작업입니다. 다양한 데이터를 대상으로 선형대수(Linear Algebra) 연산에 numpy의 sum 함수을 사용하면 매우 편리합니다. 그러나 처음 numpy의 sum 함수를 접하면 axis 파라미터 때문에 굉장히 어렵게 느껴집니다. axis를 기준으로 합을 계산하는 의미를 이해하기 어렵습니다. 이제부터 numpy의 sum 함수에서 axis가 무엇을 의미하는지 알아보겠습니다.
sum 함수의 axis 설정에 따라 결과가 완전히 달라지는 것을 확인할 수 있습니다.
이제부터 axis 파라미터가 어떤 의미가 있는지 살펴보겠습니다.
선형 대수의 데이터의 유형
데이터 분석의 각종 계산을 돕는 학문이 바로 선형대수(linear algebra)입니다.
선형대수를 사용하면 대량의 데이터를 포함하는 복잡한 계산 과정을 간단한 수식으로 표현할 수 있습니다.
선형대수의 데이터 유형은 데이터의 수와 형태에 따라서 스칼라(scalar), 벡터(vector), 행렬(matrix), 텐서(Tensor)로 구분됩니다. 각 데이터 유형에 대하여 간단하게 살펴보겠습니다.
스칼라: scalar
스칼라는 하나의 숫자만으로 이루어진 데이터를 의미합니다. 스칼라는 보통 x 와 같이 알파벳 소문자로 표기하며 실수(real number)인 숫자 중의 하나이므로 실수 집합 “R“의 원소라는 의미에서 다음과 같이 표기한다.
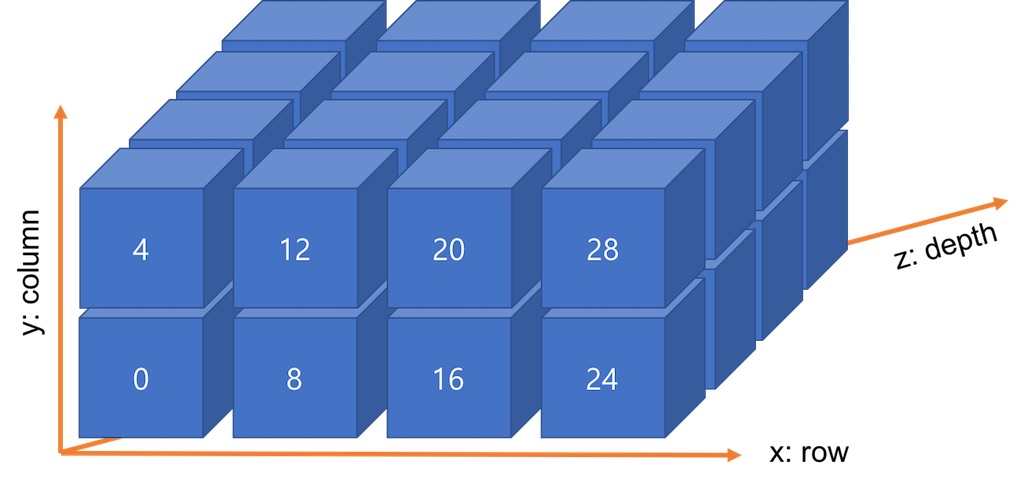
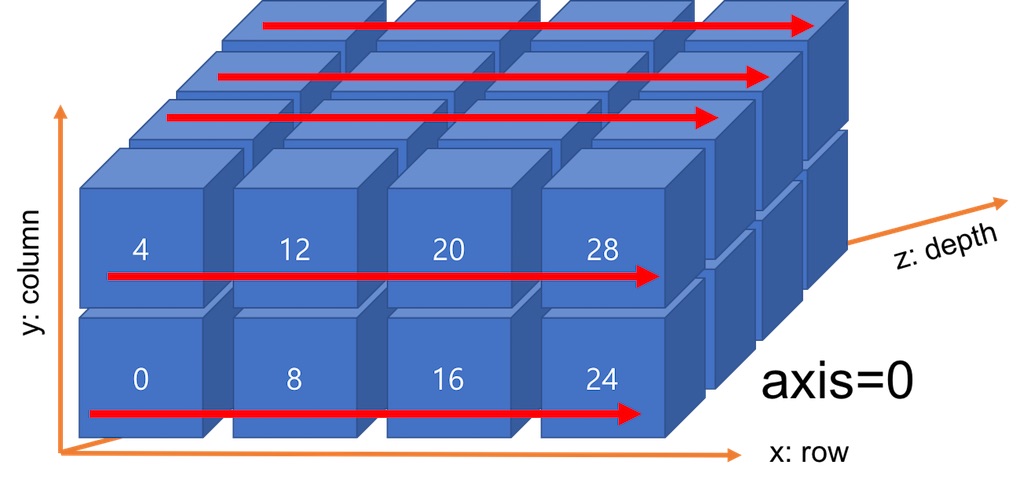
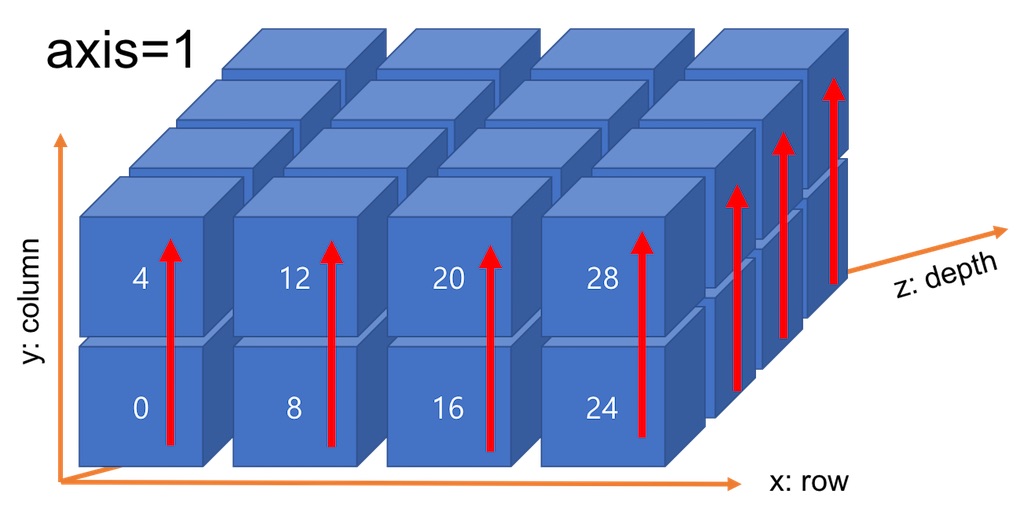
axis=1의 합산 방향은 <그림 6>와 같습니다. 결과적으로 컬럼(column)을 합치는 과정입니다.
그림 6:
다차원 배열에서 axis=1의 합산 방향
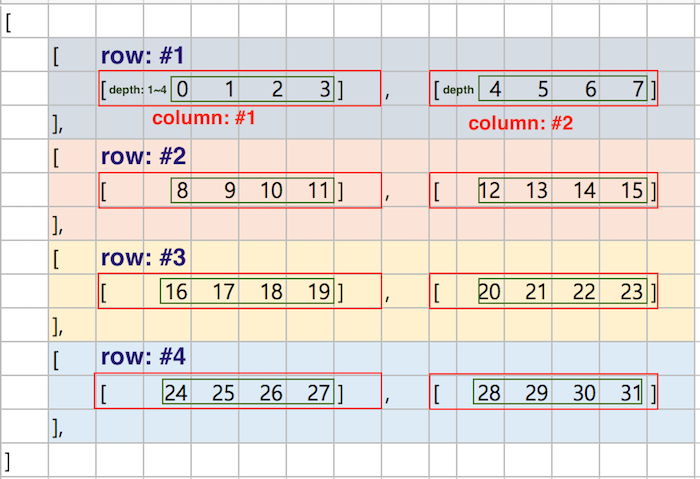
axis=1은 가장 외각에서 두 번째 괄호를 제거하는 이미지를 상상하시면 편리합니다. <그림 7>과 같이 각 row에서 컬럼을 구분하는 괄호를 제거하고, 각 컬럼의 데이터는 위치별로 합산합니다. 결과적으로 row 별로 컬럼들의 depth 위치별 합이 계산됩니다.
그림 7:
다차원 배열에서 axis=1의 합
<그림 7>은 shape (4, 2, 4)의 데이터에 sum(axis=1)를 적용하는 과정을 설명합니다. 각 요소에 색은 합산되는 그룹을 의미합니다. row 별로 4번의 합이 계산되고 4개의 row에서 총 16번의 합이 계산됩니다. 결과로 Shape(4, 4)가 반환됩니다. 각 row 별로 컬럼들의 동등 depth 요소들의 합이 반환됩니다.
case 4: axis=2
axis=2는 z축을 기준으로 합을 구하는 방식입니다. z축 dpeth 요소를 합치는 연산입니다. shape이 (4, 2, 4)인 데이터를 z축을 기준으로 합산하면 결과 shape은 depth를 제거한 (4, 2)가 반환 됩니다. 각 컬럼의 depth는 1개의 스칼라값으로 변환됩니다.
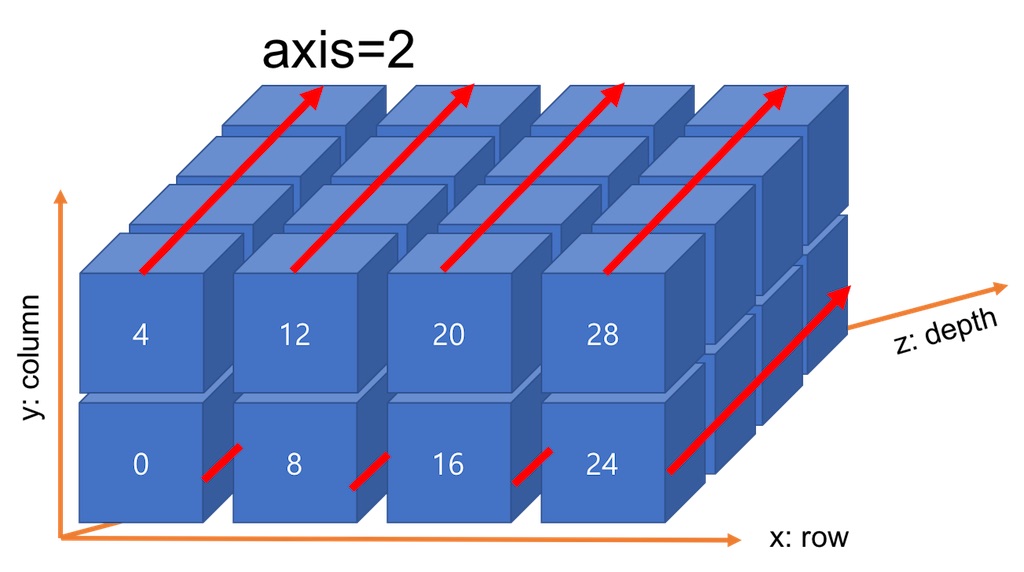
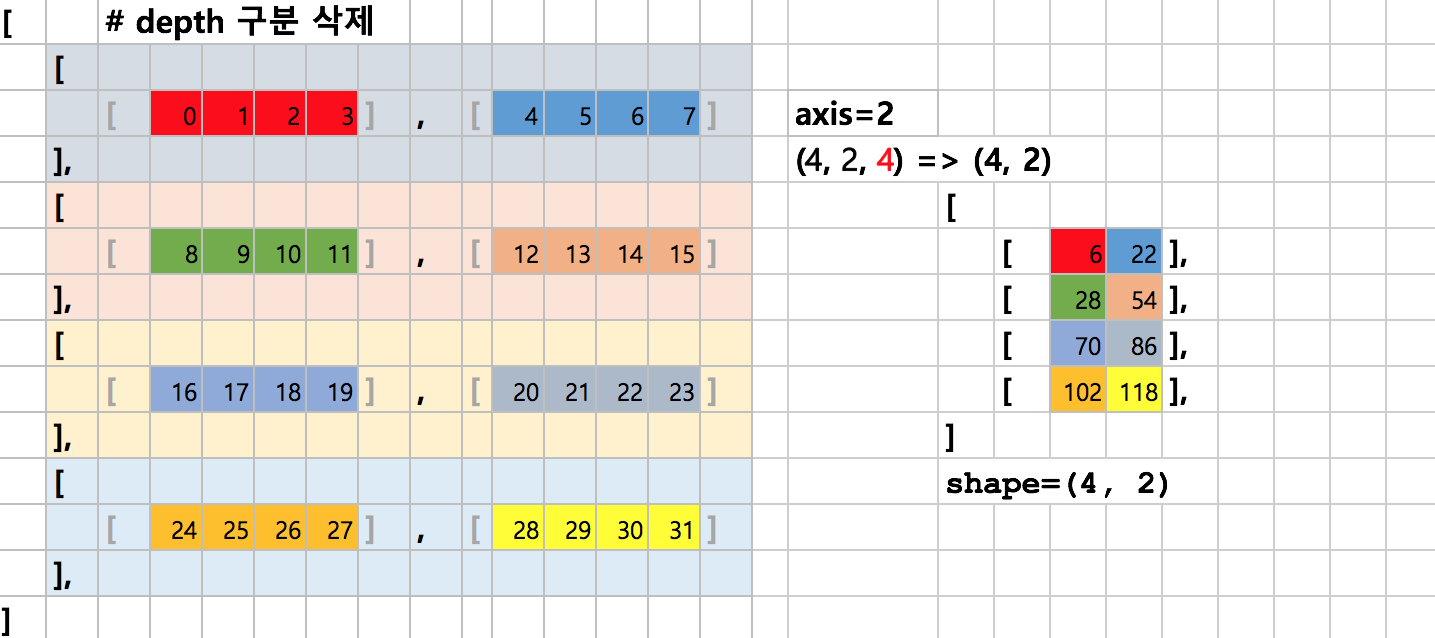
axis=2의 합산 방향은 <그림 8>과 같습니다. 결과적으로 각 row에 위치하는 컬럼이 갖는 Depth는 1개의 스칼라값으로 변환됩니다.
그림 8:
다차원 배열에서 axis=2의 합산 방향
axis=2는 depth를 묶는 괄호를 제거하는 이미지를 상상하시면 편리합니다. <그림 9>와 같이 각 column에서 Depth를 구분하는 괄호를 제거하고, 모든 Depth 요소를 합산합니다. 결과적으로 예제에서 각 row의 컬럼들은 1개의 스칼라값으로 변환됩니다.
그림 9:
다차원 배열에서 axis=2의 합
<그림 9>는 shape (4, 2, 4)의 데이터에 sum(axis=2)를 적용하는 과정을 설명합니다. 각 요소에 색은 합산되는 그룹을 의미합니다. row 별로 2번의 합이 계산되고 4개의 row에서 총 8번의 합이 계산됩니다. 결과로 Shape(4, 2)가 반환됩니다. 각 row별로 각 컬럼은 depth 요소들의 합인 스칼라값을 갖습니다.
마치며
Numpy로 선형대수를 프로그래밍할 때 자료형의 Dimension과 자료형의 기준 축에 대하여 정리해 보았습니다.
sum 함수의 매개변수를 기준으로 axis는 다음과 같은 의미가 있습니다.
axis=None은 기본값으로 모든 요소의 값을 합산하여 1개의 스칼라값을 반환합니다.
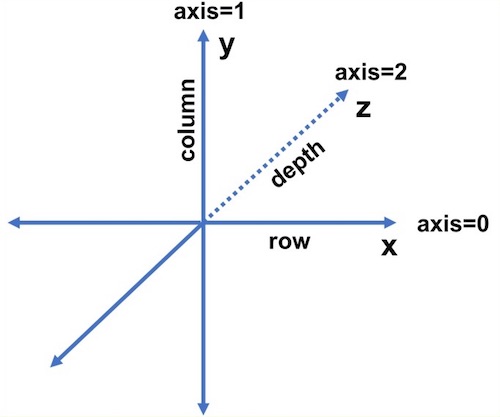
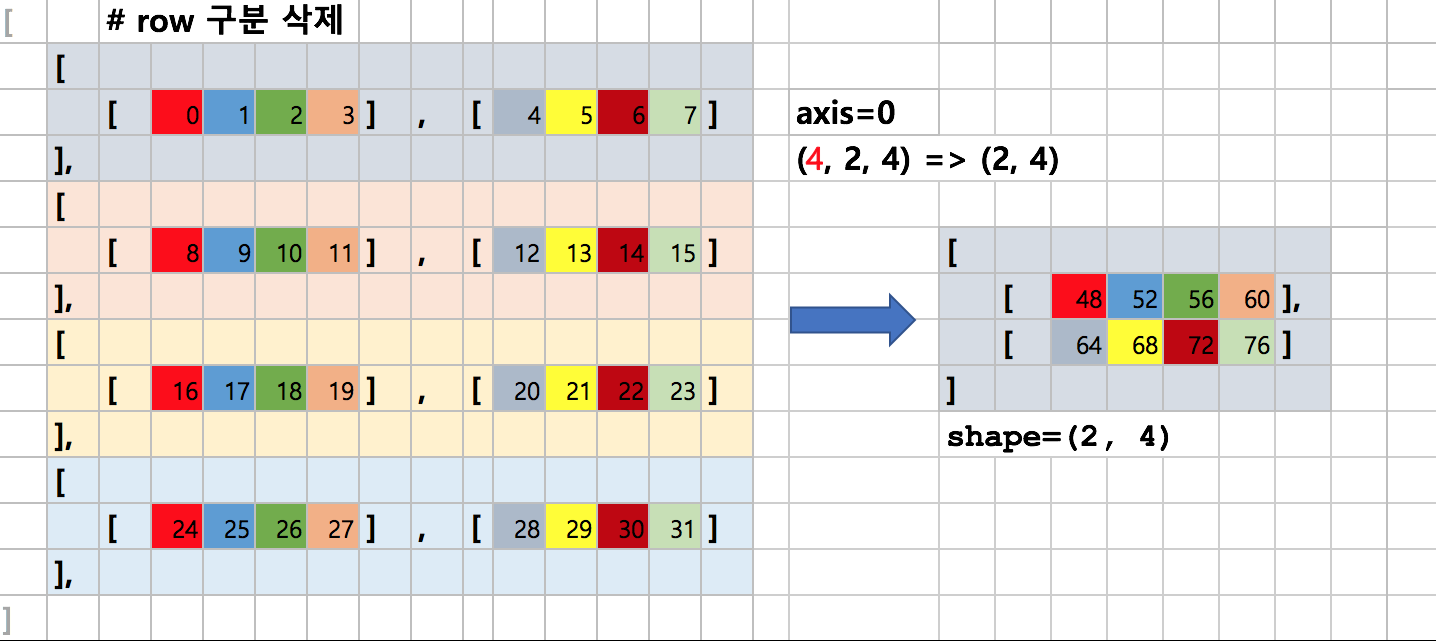
axis=0은 x축을 기준으로 여러 row를 한 개로 합치는 과정입니다.
axis=1은 y축을 기준으로 row 별로 존재하는 column들의 값을 합쳐 1개로 축소하는 과정입니다.
axis=2는 z축을 기준으로 column의 depth가 가진 값을 축소하는 과정입니다.
3차원 배열로 만들어진 Tensor의 경우 axis=2를 계산할 때 column은 스칼라값(Depth가 스칼라로 계산됨)이 됩니다.
4차원 이상의 배열로 확장될 경우 이와 같은 방식으로 개념을 적용하고 확장할 수 있습니다.