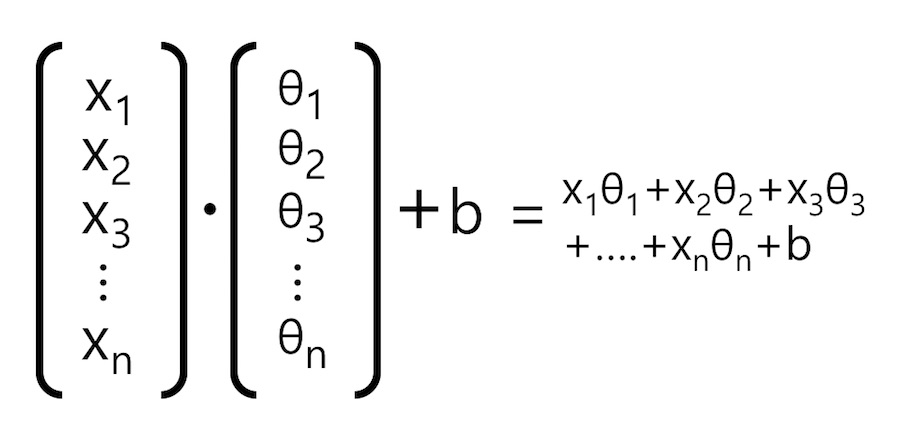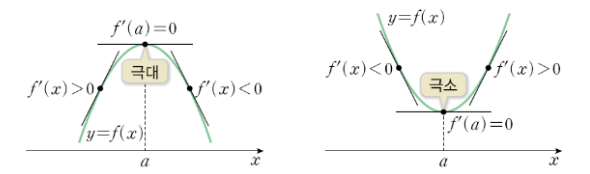이 문서에서는 여러 수식을 사용합니다. 수식에서 스칼라, 벡터, 행렬을 다음과 같은 표기법을 사용할 것입니다.
$w$: 스칼라, 소문자 표기는 스칼라를 의미합니다. 예제에서는 가중치 1개를 의미합니다.
$\boldsymbol{w}$: 벡터, 소문자 볼츠체는 벡트를 이미합니다.
$W$: 행렬, 대문자는 행렬(Matrix)을 의미합니다.
본문에서 $\theta$와 $\boldsymbol{w}$는 모두 가중치 벡터를 의미합니다.
1. 지도학습이란?
지도학습의 데이터는 사례와 라벨로 구성됩니다. 여기서 사례(Example, Instance)란 우리가 알고 있는 과거의 경험, 수집 및 측정한 데이터입니다. 라벨은 해당 사례의 실제 결과입니다. 지도학습은 사례을 입력할 때 최대한 라벨에 근접한 예측 값를 반환하는 모델을 완성하는 과정입니다.
여기서 모델이 완성이란 구체적으로 무엇을 의미하는 걸까요? 선형회귀는 다음과 같은 모델을 사용합니다.
위 모델에서 $x_n$는 입력 데이터인 사례의 특성입니다. 위 모델은 n개의 특성을 갖는 데이터가 입력됩니다. $\theta_n$은 각 입력 특성을 강화하거나 약화 시키는 가중치입니다. 위 모델은 n개의 특성과 n개의 가중치의 수식을 <그림 1>과 같이 벡터로 표현할 수 있습니다.
그림 1:
입력 데이터와 가중치의 벡터 표기
<그림 1>과 같이 입력 특성과 가중치를 벡터로 사용하면 <수식 2>와 같이 선형 회귀 수식을 간단하게 표현할 수 있습니다.
<수식 2>에서 미지수는 가중치 벡터입니다. 입력 데이터에 대하여 예측값이 라벨에 초대한 근접하도록 지속적으로 가중치 벡터를 최적화하는 과정이 선형회귀 학습의 본질입니다. 따라서 사례를 입력으로 예측 값과 라벨의 오차를 근거로 가중치를 조절하기 때문에, 머신러닝의 핵심은 오차를 관리하고 변화를 추적하는 것 입니다.
2. 오차함수와 비용함수
각 사례의 오차를 계산하는 함수를 오차함수(Error Function, Loss Function)이라고 합니다. 머신러닝은 여러건의 사례를 묶어서 1개의 단위로 처리합니다. 예를 들어 100개 사례를 하나의 묶음으로 처리한다면 100개 사례의 개별적인 오차를 오차 하수로 계산합니다. 그리고 100개의 오차를 합쳐서 오차를 관리합니다. 이렇게 1개 단위의 오차를 합치는 함수를 비용함수(Cost Function)라고 합니다.
선형회귀에서 각 사례의 오차는 다음 수식과 같이 일반적으로 라벨과 예측값의 차이의 제곱을 사용합니다.
$$
ErrorFunction= (\hat{y}^{(i)}-y^{(i)})^2
$$
<수식 3>: 오차함수(Error Function, Loss Function)
$\hat{y}^{(i)}$: i번째 사례의 예측 값
$y^{(i)}$: i번째 사례의 라벨
선형회귀에서는 비용함수로 MSE(Mean Square Error)를 주로 사용합니다. MSE의 비용함수의 수식은 다음과 같습니다.
<수식 4>의 MSE(Mean squared error, 평균 제곱 오차)는 m개의 사례에 대한 개별적인 오차의 제곱의 평균을 계산하는 비용함수입니다. 일반적으로 머신러닝에서 m은 한번에 처리하는 사례의 단위이며, m개 사례 단위로 비용 함수를 처리하고 그 결과를 기준으로 기중치를 조정합니다.
머신러닝을 위해서 준비한 학습용 사례 건수가 n X m이고 m개 단위로 비용함수를 계산하고 가중치를 업데이트 할 때, m개를 사례를 학습하는 단위를 미니배치(mini-batch)라고 합니다. m개 미니 배치를 n번 학습하여 모든 사례를 처리한 단위를 에폭(epoch)이라고 합니다.
3. 경사하강법을 이용한 학습
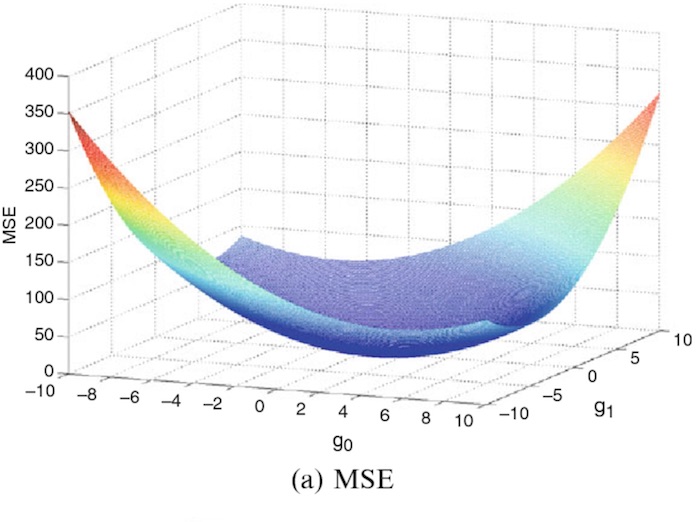
머신러닝에서 가중치를 학습시키기 위해서 기본적으로 경사하강법(Gradient Descent)을 사용합니다. 효과적으로 최적의 가중치를 찾기 위해서 비용함수는 볼록함수로 디자인합니다. 비용함수로 자주 사용하는 MSE는 대표적인 볼록함수입니다.
그림 2:
MSE, Convex Function
<그림 2>는 가중치가 3개일 때의 MSE의 그래프를 시작화한 것입니다. 특성이 4개 이상이 되면, 가중치가 4개 이상이돼기 때문에 그래프를 시작화할 수 없습니다. 결과적으로 4차원 이상의 MSE에서는 현재 가중치가 비용함수에 미치는 경향을 파악하기 어렵습니다.
현재 가중치가 비용함수에 미치는 경향을 파악하기 위해서 미분2을 사용합니다. MSE 비용함수를 미분함하여 도함수를 구하고, 현재 사용중인 가중치를 입력하여 미분 계수를 구합니다. 이 미분 계수를 통해서 현재 가중치가 MSE에 어떤 영향을 미치는지 확인할 수 있습니다. 특정 가중치에 대하여 미분 계수가 양수가 나온다면, 해당 가중치는 오차가 양의 방향으로 증가하는 경향을 보인다는 의미입니다. 반대로 특정 가중치에 대한 미분 계수가 음수가 나온다면, 해당 가중치는 음의 방향으로 오차가 증가하는 경향을 보인다는 의미입니다. 마지막으로 미분계수가 0이면 현재 가중치가 오차가 최소가 되면 최적의 값이라는 의미입니다. <그림 3>과 같이 미분의 극대극소의 개념을 사용하는 것 입니다.
그림 3:
미분의 극대&극소
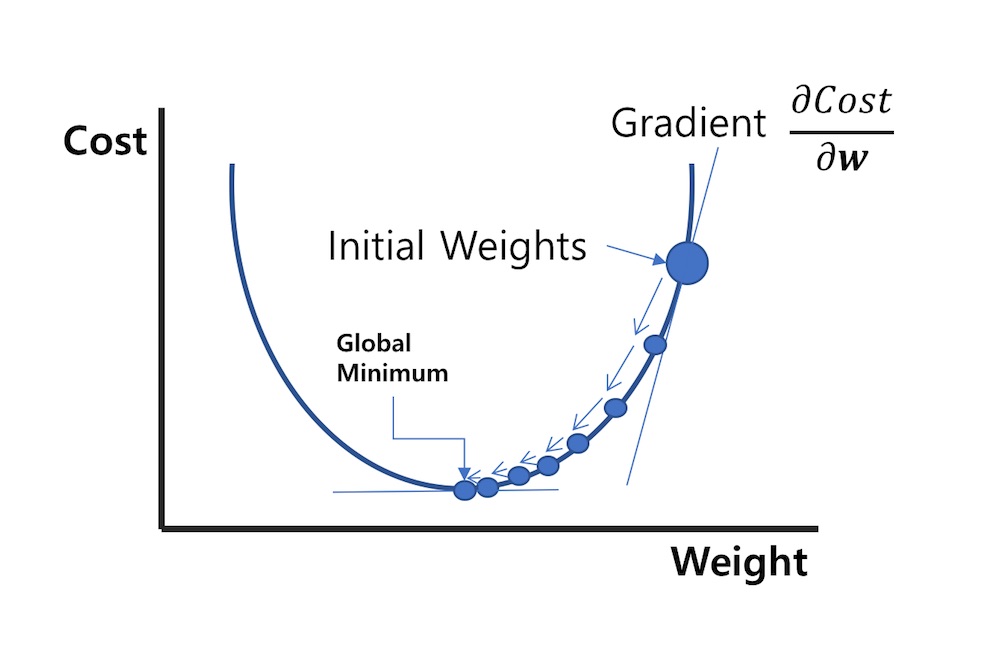
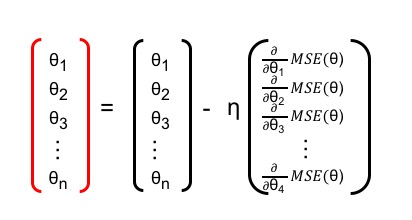
경사하강법은 미분의 극대/극소 개념을 이용하여 <그림 4>와 같이 비용함수의 변화량을 상태를 파악하고 지속적으로 가중치를 갱신합니다. 이 과정을 반복하여 비용이 최소가 되는 가중치를 찾습니다.
그림 4:
경사하강법
<그림 4>의 과정은 다음 수식으로 표현할 수 있습니다.
$$
\boldsymbol{w} = \boldsymbol{w} - \eta\frac{\partial }{\partial \boldsymbol{w}}MSE(\boldsymbol{w}, b) \\
b = b - \eta\frac{\partial }{\partial b}MSE(\boldsymbol{w}, b)
$$
<수식 5>. 가중치 갱신 수식
$\boldsymbol{w}$: 가중치 벡터
일반적으로 가중치 표시로 $\boldsymbol{w}$와 $\boldsymbol{\theta}$를 사용합니다.
$\eta$: 학습률(Learning rate)
현재 가중치의 변화량을 가중치 갱신에 적용할 때 사용하는 비율입니다.
b: 편차
현재는 숫자인 선형회귀를 대상으로 합니다. 본 문서에서 b는 벡터가 아닌 스칼라입니다.
<수식 5>에서 사용되는 가중치는 벡터입니다. 위 수식은 <그림 5>와 같은 형태로 적용됩니다. <수식 5>는 가중치 벡터의 각 가중치 별로 비용함수에 영향도를 계산하고, 그 결과를 가중치 벡터의 요소별로 적용합니다.
그림 5:
입력 데이터와 가중치의 벡터 표기
요약하면 경사하강법은 비용함수를 미분하여 현재 가중치가 비용함수에 미치는 영향을 파악하고, 그 영향도에 학습률을 곱하여 현재 가중치를 갱신하는 반복적인 과정입니다. 이 과정을 반복하여 점진적으로 비용이 최소가 되는 최적의 가중치를 찾습니다. 이렇게 반복적이고 점진적으로 가중치를 갱신하는 과정이 바로 머신러닝의 학습입니다.
MSE는 현재 가중치와 편차 두 개의 변수를 갖습니다. 따라서 편미분이 수행됩니다. 편미분시 목적 변수외에는 모두 상수 취급로 취급합니다. $h(x_1, x_2)= x_1^2+x_2^3$에 대하여 $\frac{\partial}{\partial x_1} h(x_1, x_2)=2x_1$와 $\frac{\partial}{\partial x_2} h(x_1, x_2)=3x_2^2$를 결과로 갖습니다.
$\frac{d}{dx}f(g(x)) = f’(g(x))g’(x)$의 체인룰에 의하여 미분이 진행됩니다.
4.3 MSE 편미분 - 선형대수
<수식 7>과 <수식 8>에는 수열이 포함되어 있습니다. 위 수식이 m번 수행하고 그 결과 합산하여 평균을 반환하는 방식입니다. 이 수식을 행렬로 변경할 경우 수열 수식을 제거할 수 있습니다. 또한 컴퓨터 프로그램으로 구현할 때 반복문이 제거됩니다. 이런 기법 적용을 Vectorization이라고 합니다.
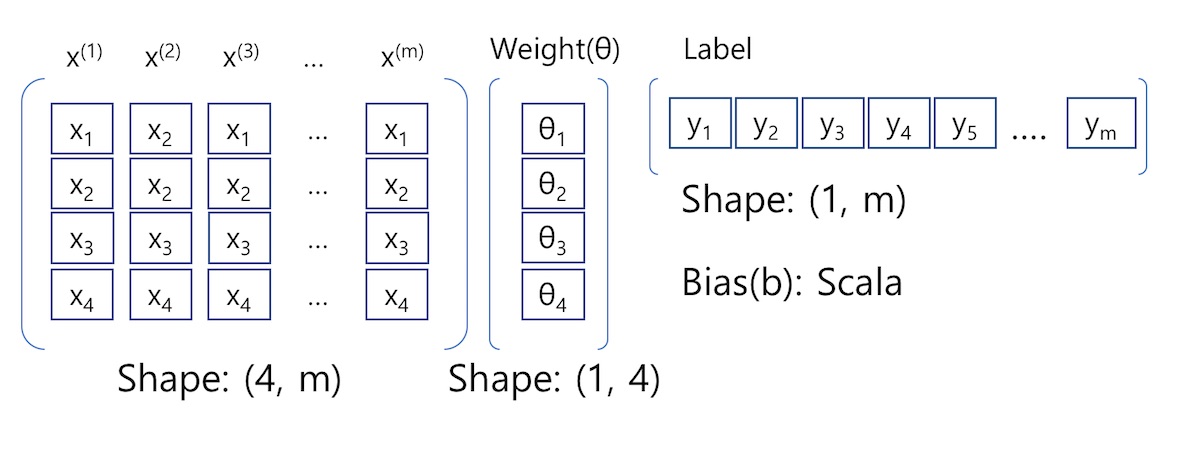
MSE를 선형대수로 전환하는 과정에서 다음과 조건을 가정합니다.
입력 데이터인 사례는 4개의 특성을 가짐
특성의 갯수 제한은 없지만 설명 및 그림을 효과적으로 전달하기 위하여 4개로 한정
1회 처리 사례 데이터 건수: m개
사례 데이터 행렬 유형: 컬럼벡터
가중치 행렬 유형: 컬럼벡터
편차: 스칼라
그림 6:
MSE 행렬 전환을 위한 행렬 형태 정의
미분 불가능 조건 - 분연속 점, 뽀족한 첨점 및 접선이 수직인 함수는 미분이 블가능 합니다. 상세 정보는 다음 링크를 참조하시기 바랍니다. 링크: 미분 불가능 조건[return]
함수의 특정 시점의 변화량을 파악하기 위해서 미분을 수행합니다. 미분의 결과를 도함수이며, 도함수에 입력값을 제공하여 계산한 결과는 미분계수입니다. 미분계수는 입력값에 대한 함수의 순간 변화율을 의미합니다.
[return]