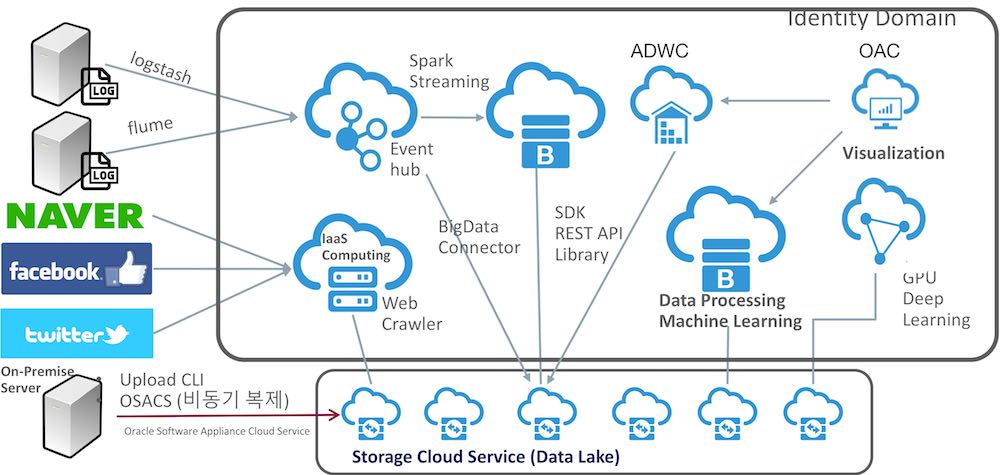
Oracle Cloud는 대용량 데이터 병렬 처리와 분석을 담당하는 빅데이터 서비스로 Big Data Cloud(이하 BDC)를 제공합니다. 오라클 클라우드에서 Data Lake는 DBMS와 하둡 HDFS가 아닌 Oracle Storage Cloud Service(이하 Storage Service)에서 제공하는 Object Storage입니다.
이 문서에서는 대용량 병렬 처리를 담당하는 BDC가 Object Storage에 데이터를 읽고/쓰기는 연동 설정과 연동 방식에 대하여 살펴보겠습니다. 오라클 클라우드는 Storage Service로 OCI Storage Classic과 OCI Storage 서비스 두 가지를 제공합니다. 이 두 가지 서비스는 Object Storage 관점에서 다음과 같이 정리할 수 있습니다.
BDC는 OCI Storage Classic과 OCI Storage를 모두 연동할 수 있습니다. 본 문서에서는 BDC와 OCI Storage Classic을 중심으로 살펴보겠습니다.
Cloud와 HDFS & Object Storage의 역할
기존에 빅데이터 인프라를 자체 데이터 센터에 구축할 경우에 분석 데이터가 모이는 Data Lake는 일반적으로 하둡의 HDFS였습니다. 그러나 클라우드에서 빅데이터 인프라를 구축한다면 Data Lake는 Object Storage로 변경됩니다.
클라우드에서 하둡 서비스를 구성할 경우, OS는 VM으로 구성되고 HDFS는 스토리지 서비스의 블록 스토리지에 설치됩니다. 이와 같은 방식으로 빅데이터 시스템을 구성할 경우, VM의 블록스토리지에서 운영되는 HDFS는 안정성이 상대적으로 떨어집니다. 데이터의 확장성, 안정성, 가용성 및 비용을 고려해 볼 때, 클라우드에서는 Object Storage가 Data Lake로 더 적합한 공간입니다.
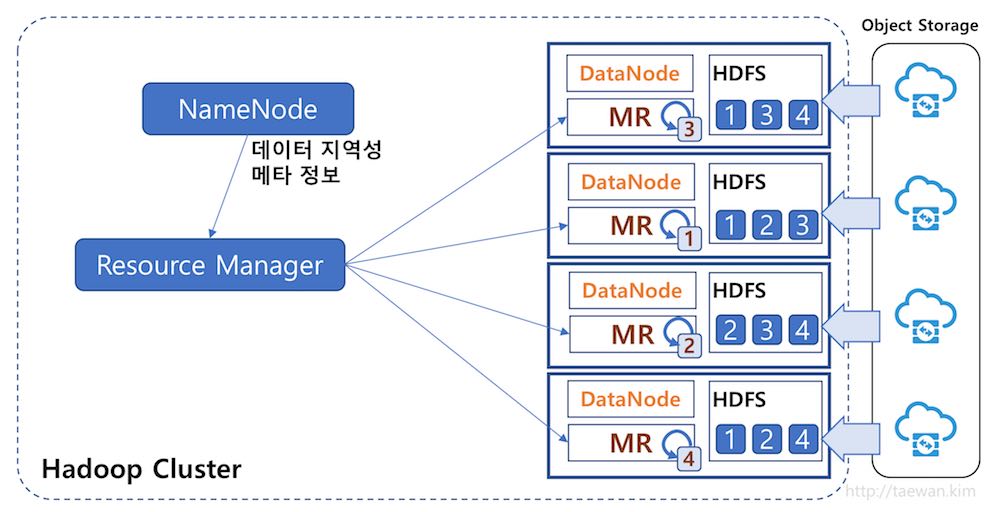
그렇다면 클라우드에서 HDFS는 어떤 의미를 가질까요? 하둡 병렬 처리 기술의 핵심은 데이터를 여러 서버에 나눠서 저장하고, 해당 데이터를 읽어서 병렬로 처리를 해야 할 때, 데이터가 있는 곳에서 해당 로직을 직접 실행하여 데이터의 네트워크 이동을 최소화한다는 점입니다. 데이터가 이동하는 것이 아니라 로직을 이동시켜서 데이터를 처리하는 방식을 데이터 지역성(“Data Locality”)라고 합니다. Data Lake로 Object Storage를 사용할 경우, 데이터 지역성의 개념이 약해집니다. 대용량 데이터를 처리할 경우 여러 데이터 블락을 나눠서 처리할 때 매번, Object Storage로 부터 하둡 클러스터의 연산 서버로 데이터를 로딩해야하기 때문에 네트워크 비용이 발생합니다.
이런 작업이 반복적으로 발생할 경우, 효율이 떨어질 수 있습니다. 때로는 HDFS에 데이터를 일차 저장한 후 다음부터는 데이터 지역성을 이용하여 데이터 병렬 처리의 효율을 높이는 방법도 필요합니다. 클라우드 빅데이터에서 HDFS는 이런 용도로 사용됩니다. 즉 클라우드에서 HDFS는 분석 대상 데이터의 임시 데이터 저장소 및 데이터 지역성을 적용하기위한 캐싱과 같은 역할을 담당합니다.
그림 1:
Hadoop의 데이터 지역성:Data Locality)
즉 클라우드의 빅데이터 시스템에서 Data Lake는 Object Storage이며, HDFS는 데이터 지역성을 높이기 위한 임시 데이터 저장소로 사용됩니다.
Oracle BDC와 Object Storage
OCI Storage Classic의 Object Storage는 OpenStack Swift를 기반으로 개발되었습니다. OpenStack Swift는 Hadoop과 Swift를 통합하는 인터페이스을 제공합니다. 이 인터페이스의 상세 소개는 다음 URL을 참조하시기 바랍니다.
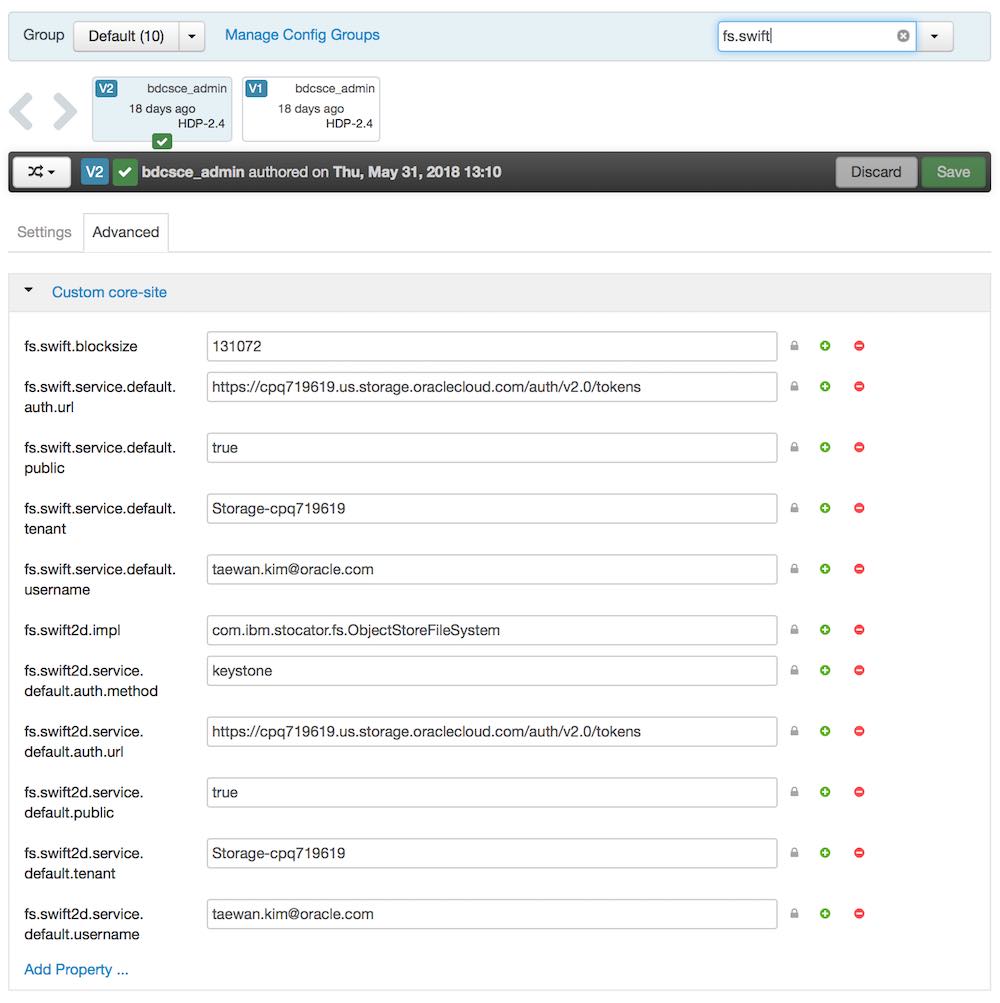
위 명령은 provider가 default로 설정되었으며, default로 등록된 Swift의 integration 컨테이너1에 저장된 파일 목록을 조회합니다. 위 예제에서 사용되는 default 프로바이더는 core-site.xml에 저장된 상태이며, 인증 정보를 런타입에 추가로 입력하는 방식을 소개합니다. 일반적으로는 인증정보까지 모두 core-site.xml에 등록하는 방식을 더 많이 사용합니다.
BDC와 Object Storage 연동 설정
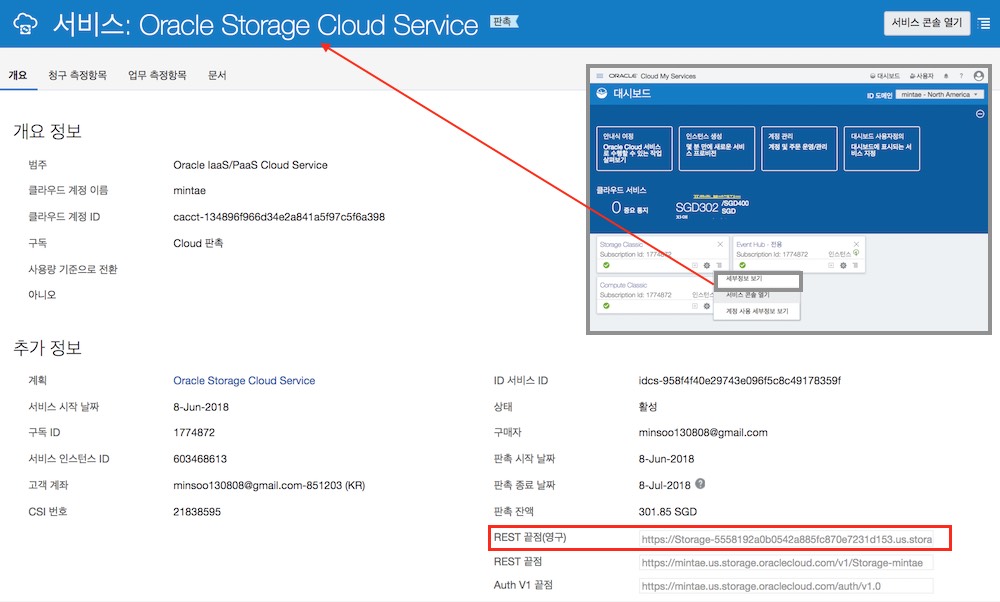
Oracle Cloud의 Object Storage 인터페이스 주소는 ‘Oracle Storage Cloud Service’ 상제 정보 조회 페이지에서 확인할 수 있습니다. Hadoop과 연동할 때 <그림 2>의 REST Endpoint(Permanent)을 이용합니다.
그림 2:
Object Storage 연동 URL 확인
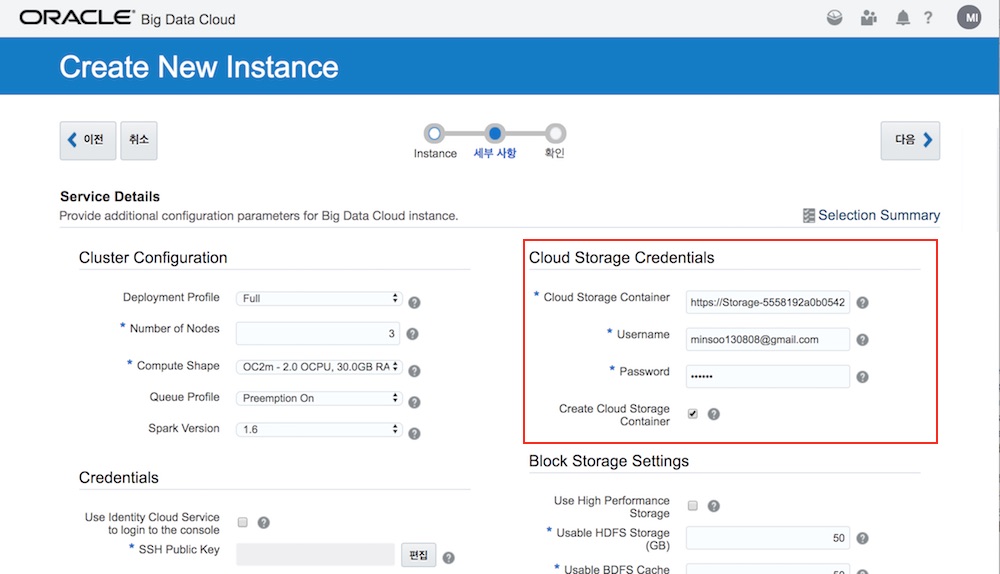
Oracle BDC 인스턴스를 생성할 때, Object Storage 영동에 필요한 정보를 등록합니다. <그림 3>은 BDC 생성 시 Object Storage를 설정하는 부분입니다.
위와 같은 설정으로 BDC 인스턴스를 생성하면, 이 정보를 기반으로 Oracle BDC 인스턴스와 Object Storage를 통합하는 설정이 core-site.xml에 추가됩니다. 이 설정 내용은 Ambari를 통해서 확인할 수 있습니다.
그림 4:
Object Storage와 BDC의 연동 설정 - Ambari View
<그림 4>에서 확인할 수 있는 것처럼, 기본으로 설정된 명은 default입니다.
BDC와 Object Storage 연동
BDC 인스턴스는 Object Storage와 연동된 설정이 적용된 상태입니다. BDC의 hadoop 명령, MapReduce 및 Spark에서는 swift://<container_name>.<provider_name>/<path> 패턴으로 Object Storage 파일을 읽고 쓸 수 있습니다.
Hadoop Shell
Hadoop FS(File System) shell을 이용하여 Object Storage의 데이터를 조회, 추가, 삭제 및 복사할 수 있습니다.
(1) hadoop fs - 파일 목록 조회
Hadoop FS(File System) shell을 이용하여 Object Storage의 integration 컨테이너의 파일 목록을 조회할 수 있습니다.
Hadoop FS(File System) shell을 이용하여 Object Storage의 integration 컨테이너에 디렉터리 개념의 파일을 추가할 수 있습니다. 파일명에 디렉토리 구조를 기술하여 마치 디렉터리 구조가 지원되는 것처럼 사용하는 것이 Swift의 일반적인 패턴입니다.
Object Storage의 Integration 컨테이너 파일을 읽은 후, MR 작업 수행 후 Obejct Storage에 그 결과를 기록하는 예제입니다.
다음은 MapReduce의 드라이버 코드입니다. 실행 인자로 입력 파일과 출력 디렉터리를 지정받는 형태입니다.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(MRWordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
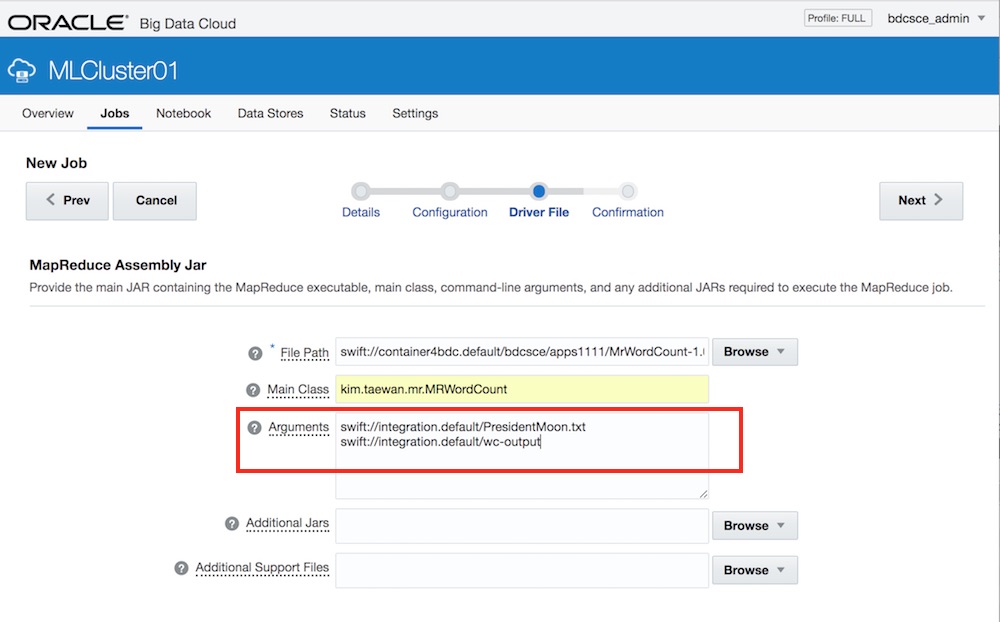
아래 <그림 5>는 MRWordCount를 Job으로 등록하는 UI입니다. 등록 시 실행 인자로 Object Storage의 파일과 출력 디렉터리를 사용하고 있습니다.
그림 5:
MapReduce Job 등록 - 인자로 소스 파일과 출력 디렉터리 지정
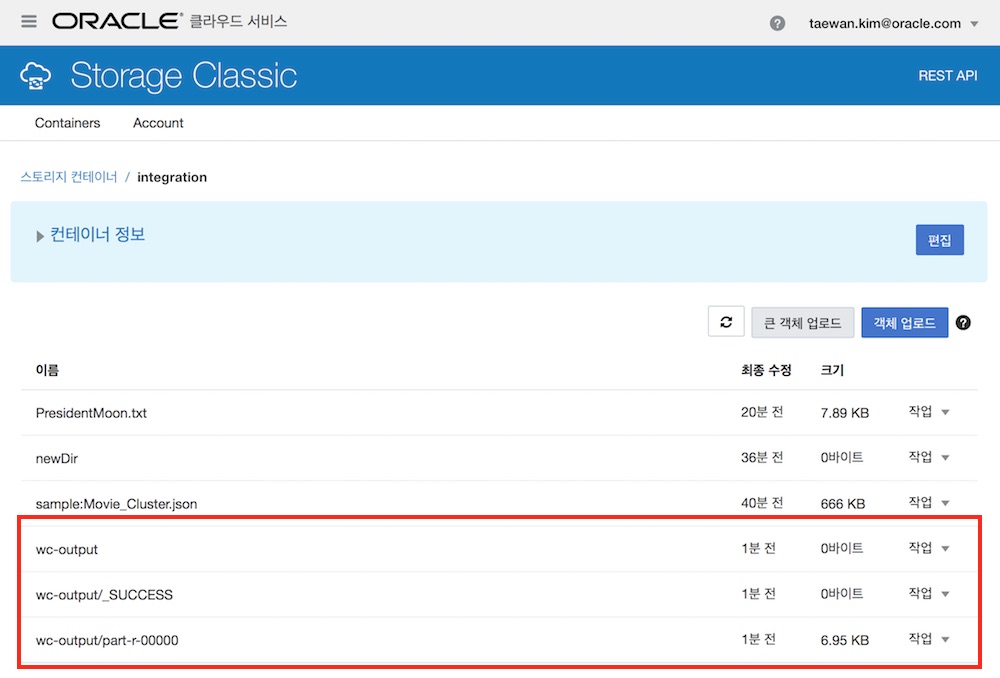
아래 <그림 6>은 MRWordCount Job의 실행 결과입니다. Object Storage에 출력 결과가 등록된 것을 확인 할 수 있습니다.
그림 6:
MapReduce Job 등록 - 인자로 소스 파일과 출력 디렉터리 지정
Spark 연동
다음 코드는 spark 데이터프레임으로 파일을 읽고, WordCount 예제입니다. 파일 소스와 출력을 모두 Object Storage로 설정하였습니다.
val source = "swift://integration.default/PresidentMoon.txt"
val df = spark.read.text(source)
val wordDF = df.select(explode(split(col("value"), " ")).as("word"))
val result = wordDF.groupBy("word").count
result.write.format("csv").save("swift://integration.default/spark-output")
위 코드의 처리 결과는 csv 파일 형태로 Object Storage에 저장됩니다. 다음은 integration 컨테이너에 저장된 파일 목록입니다.
클라우드 빅데이터 시스템을 구성할 때, 하둡 클러스터가 VM기반으로 구성된다면 데이터 레이크 역할은 Object Storage가 담당하는 것이 효과적입니다.
Oracle BDC는 Object Stroage와 완전하게 통합되어 있습니다. 오라클 클라우드의 Object Storage는 OpenStack Swift 호환 인터페이스를 제공하면, 이 인터페이스를 이용하여 하둡과 통합 구성됩니다.
Oracle BDC는 인스턴스 생성 시 입력된 Object Storage와 인증 정보를 이용하여 Object Storage와 BDC Hadoop의 통합 설정이 적용됩니다. 이 설정을 통해서 Hadoop FS Shell, MapReduce 및 Spark에서 HDFS를 지정하는 경로에 Object Storage의 경로를 설정할 수 있습니다. Object Storage 경로를 설정할 때, 프로토콜로 swift를 사용합니다. 또한 통합 설정에 적용된 프로바이더 명과 컨테이너 명을 이용합니다.
Object Storage가 Hadoop에 완전하게 통합된 BDC는 다음과 같은 잇점을 제공할 수 있습니다.
안전하고, 확장성이 보장되며 비용적으로 저렴한 Data Lake 지원
Object Storage를 사용할 경우 문제가 되는 데이터 지역성을 Hadoop HDFS로 보완
Object Storage와 HDFS의 통합을 통해서 Object Storage의 안정성과 확장성, HDFS의 기존 편의성을 모두 지원
HDFS를 Object Storage의 캐싱 레이어로 활용
OCI Storage Classic의 Object Storage는 데이터를 저장하는 최상위 개념으로 컨테이너를 사용합니다. 컨테이너에는 여러 파일(객체)이 저장될 수 있습니다. 그러나 컨테이너는 다른 컨테이너를 포함할 수 없습니다. 컨테이너 아래의 폴더 구조를 지원하기 위해서 파일명으로 “폴더명1/폴더명2/파일명” 형태의 패턴을 사용합니다. 이 파일명 패턴을 이용하여 컨테이너 아래에 폴더 구조를 사용할 수 있습니다.
[return]